
GstarCAD 2026 is een commercieel CAD programma, wat cross-platform ontwikkeld wordt. Deze applicatie wordt aangeboden als de concurrent van de welbekende Autodesk applicatie Autocad. Ze claimen zelfs 100% compatible te zijn met de Autocad data formats. Het grootste verschil zou hem in de licentie prijs zitten.
GStarCAD wordt voor Linux alleen als debian (.deb) pakket aangeboden op de website van GStarCAD. Aangezien ik Fedora gebruik is dit wat onhandig. Er zijn meerdere mogelijkheden om hier mee om te gaan, maar ik heb gekozen voor toolbox. Deze tool wordt standaard met Fedora meegeleverd en is effectief een container systeem gemaakt met Podman waarin een distributie zoals Ubuntu gebruikt kan worden. De software binnen deze container ziet dan de container als het OS maar kan daarbij wel bij de lokale bestanden komen. Er worden meerdere onderdelen vanuit het host OS gedeeld zodat je ook grafische programma's kan gebruiken.
Via de download pagina op website kan zowel de Window, macOS en Linux versie gedownload worden. De button op de voorpagina geeft alleen de windows .exe, maar daar hebben we niks aan.
Omdat we een Ubuntu omgeving nodig hebben, kunnen we deze aanmaken met toolbox create. Via toolbox enter kunnen we vervolgens de omgeving starten. Dit gaat dus alleen via de command-line:
toolbox create --distro ubuntu --release 25.04
toolbox enter ubuntu-toolbox-25.04
Via enter wordt dus de omgeving gestart en zitten we in eens in een Ubuntu shell. Hierna kunnen we het .deb pakket installeren. Een wat onhandig iets aan deze methode is dat de afhankelijkheden niet standaard geïnstalleerd worden. Deze moeten dan nog extra geïnstalleerd worden. Door te elke keer te starten en de melding af te wachten ben ik tot de onderstaande oplossing gekomen:
sudo dpkg -i ./Downloads/GstarCAD2026EN_V2511.deb
sudo apt install libnss3 libxdamage1 libxss1 libasound2t64 libxslt1.1 liblcms2-2 libglapi-mesa libxcb-dri2-0 libxcb-icccm4 libxcb-image0 libxcb-keysyms1-dev libxcb-render-util0-dev libxcb-xkb1 libxkbcommon-x11-0 xdg-desktop-portal-gtk
Vooral xdg-desktop-portal-gtk is een interessante. Zonder deze werkt alles prima, behalve dat de muis cursor op hoog DPI schermen, enorm klein is. Nadat dit pakket is toegevoegd, is dat opgelost.
Gstarcad is in /opt/apps/gstarsoft.gstarcad2026 geïnstalleerd. Opstarten kan dan via het volgende commando:
/opt/apps/gstarsoft.gstarcad2026/files/gcad.sh
Applicaties in een Toolbox omgeving worden niet automatisch opgepakt in het applicatie overzicht. Daar is wat handwerk voor nodig. Wel is er in de toolbox omgeving een .desktop file hiervoor. Hiervoor moet ook het icon bestand gekopieerd worden vanuit de toolbox:
# In de toolbox
cp /usr/share/icons/hicolor/scalable/apps/gstarsoft.gstarcad2026.png ~/Downloads/
# Terug op de host
mv ~/Downloads/gstarsoft.gstarcad2026.png ~/.local/share/icons/
Maak vervolgens een ~/.local/share/applications/gstarcad.desktop file aan met de onderstaande inhoud. Hierna zal de applicatie beschikbaar moeten zijn in de app launcher:
[Desktop Entry]
Version=1.0
Encoding=UTF-8
Type=Application
Categories=Graphics;Viewer;
Terminal=false
GenericName=GstarCAD 2026
GenericName[zh_CN]=浩辰CAD 2026
Comment=浩辰CAD 2026
Comment[zh_CN]=浩辰CAD 2026
Name=GstarCAD 2026
Name[zh_CN]=浩辰CAD 2026
MimeType=image/vnd.dwg;application/dwg;image/vnd.dxf;application/dxf;application/dwf;application/dwfx;application/dwt;;model/vnd.dwf;model/vnd.dwfx
Icon=$HOME/.local/share/icons/gstarsoft.gstarcad2026.png
Exec=toolbox run --container ubuntu-toolbox-25.04 /opt/apps/gstarsoft.gstarcad2026/files/gclauncher.sh %F
Wat direct opvalt als je de logs bij het starten van de applicatie terug ziet, is dat deze applicatie met QT is gemaakt. Deze toolbox is natuurlijk uitermate geschikt om cross-platform applicaties te bouwen. De applicatie onder Windows, macOS en Linux ziet er hiermee ook helemaal gelijk uit. Dit volgt hierbij wel een Windows UI filosofie, wat natuurlijk wel wat scheef staat op die van macOS en Linux desktops.

In Fedora (en vermoedelijk veel meer Linux distributies) wordt de klik op het scroll-wieltje van de muis (als je muis dit heeft) als een plak commando (control + v) uitgevoerd. Ik vind dit niet heel handig. MacOS gebruikt standaard de middle click van de muis om het overzicht van je openstaande apps te tonen. Dit gebruik ik nogal veel om tussen applicaties te schakelen.
Het aanpassen van de middle click op linux is niet een kwestie van het open van de de configuratie instellingen, helaas. Maar er is een relatief makkelijke methode. Er is een tool die input-remapper heet. Deze kan voor Fedora via de command-line geinstalleerd worden. Ik gebruik Silverblue:
rpm-ostree install input-remapper
Na een reboot is de GUI van input-remapper tussen de rest van de app's te vinden. Let wel op dat de tool niet de schoonheidsprijs voor werkbaarheid verdient. Je zal even moeten wennen aan hoe het opgezet is.
Allereerst wordt er in het table devices alles getoond wat een input device is. Ik gebruik een Keychron muis, met z'n bijgeleverde dongle (dus niet direct via Bluetooth).
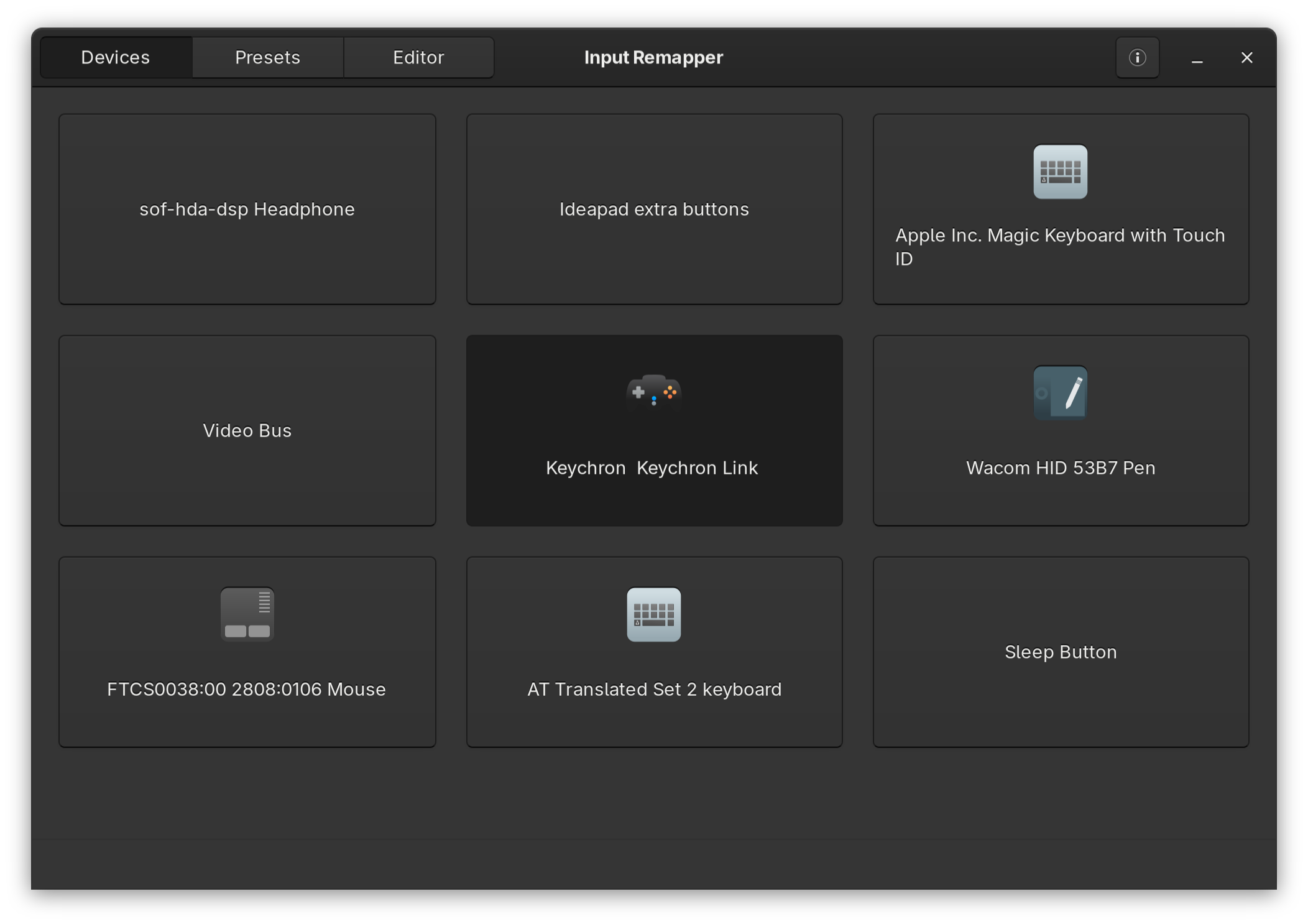
Als je op het device klikt kom je in het tabje presets. Standaard staat hier al een new preset. Dit is een lege preset die je kan aanpassen. Je kan natuurlijk ook op new klikken om er nog 1 toe te voegen.
Wat een beetje verwarrend is, is dat bovenaan de apply te zien is, met daaronder een rename input box. Ik zou persoonlijk dit deel meer naar beneden neerzetten. Links onder zie je het deel input. Hier kan je één of meerdere inputs neerzetten. Ik voeg er 1 toe met de text BTN_MIDDLE. Je kan hiervoor ook record gebruiken. Als deze regel daarna geselecteerd is, wordt het output deel actief. Ik heb deze op Key or Macro staan met als target keyboard. Vervolgens kan je de toetscombinatie die je wilt gebruiken toevoegen.
Belangrijk is dat je geen combinatie gebruikt die al door iets anders wordt gebruikt. Een combinatie van diverse toetsen is denk ik de beste route. In dit voorbeeld gebruik ik de linker control met de o (wat niet een hele ingewikkelde is). Wat ook nog wat verwarrend is, als de input box actief is, laat hij de toetscombinatie zien die je indrukt. Dit is alleen een preview, je zal hem dan alsnog moeten overtypen in de input box. Voor control+o type je dan Control_L + o. Volgens mij zijn de spaties hierbij ook belangrijk.
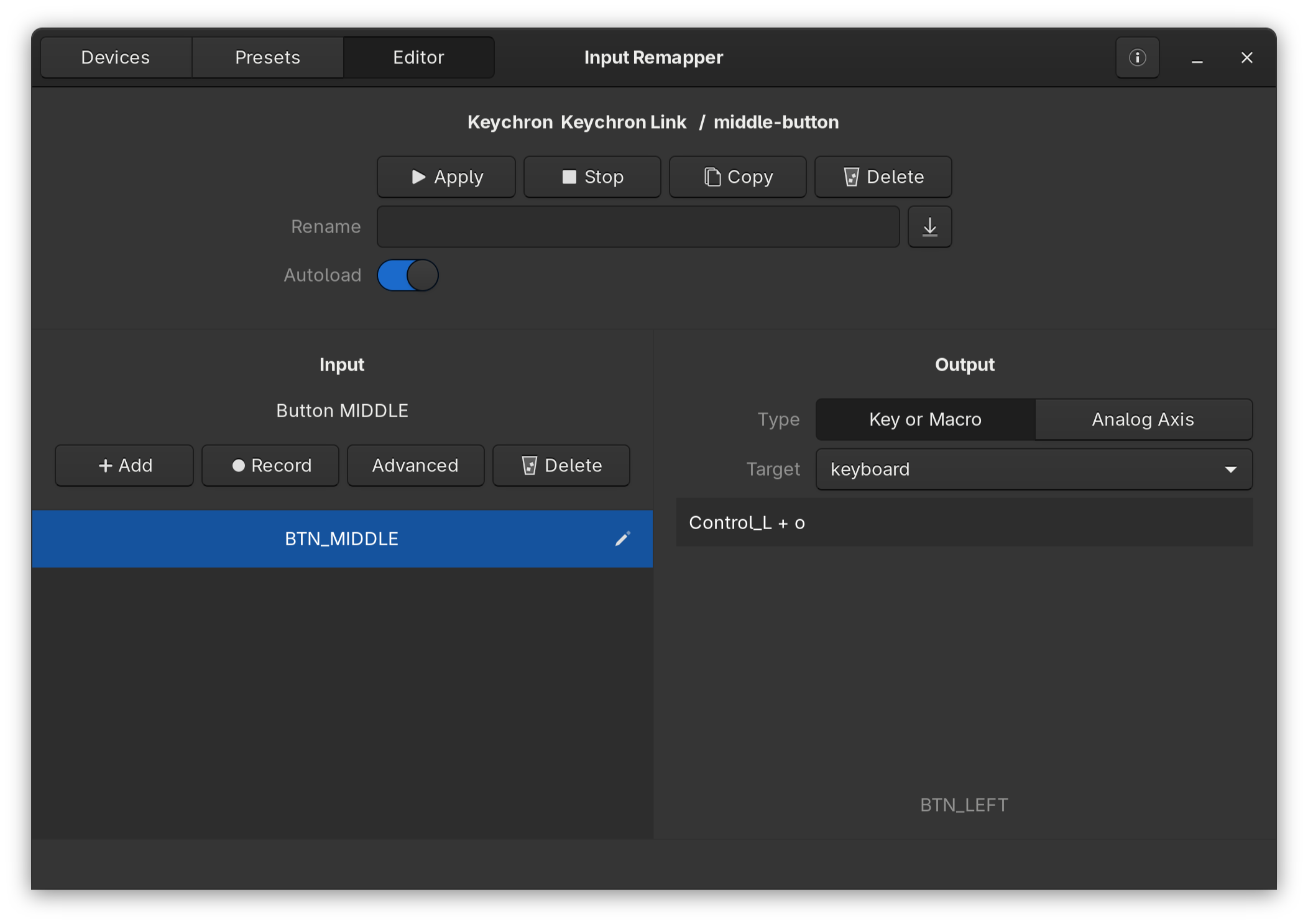
Als je hierna bovenaan apply klikt (en ik heb autoload ook aangezet voor na een reboot) dan zal deze toetscombinatie uitgevoerd worden bij het klikken op de middelste knop.
Binnen Gnome kan je vervolgens via de configuratie instellingen naar shortcuts gaan om aan het overview een toets te koppelen. Interessant is dat de super/meta key hier niet gedefinieerd is. Deze zal op een lager niveau in Gnome zijn vast gelegd en niet zomaar aan te passen zijn. Als je vervolgens op "show overview" klikt kan je de toetscombinatie aangeven, door de middelste knop te klikken.
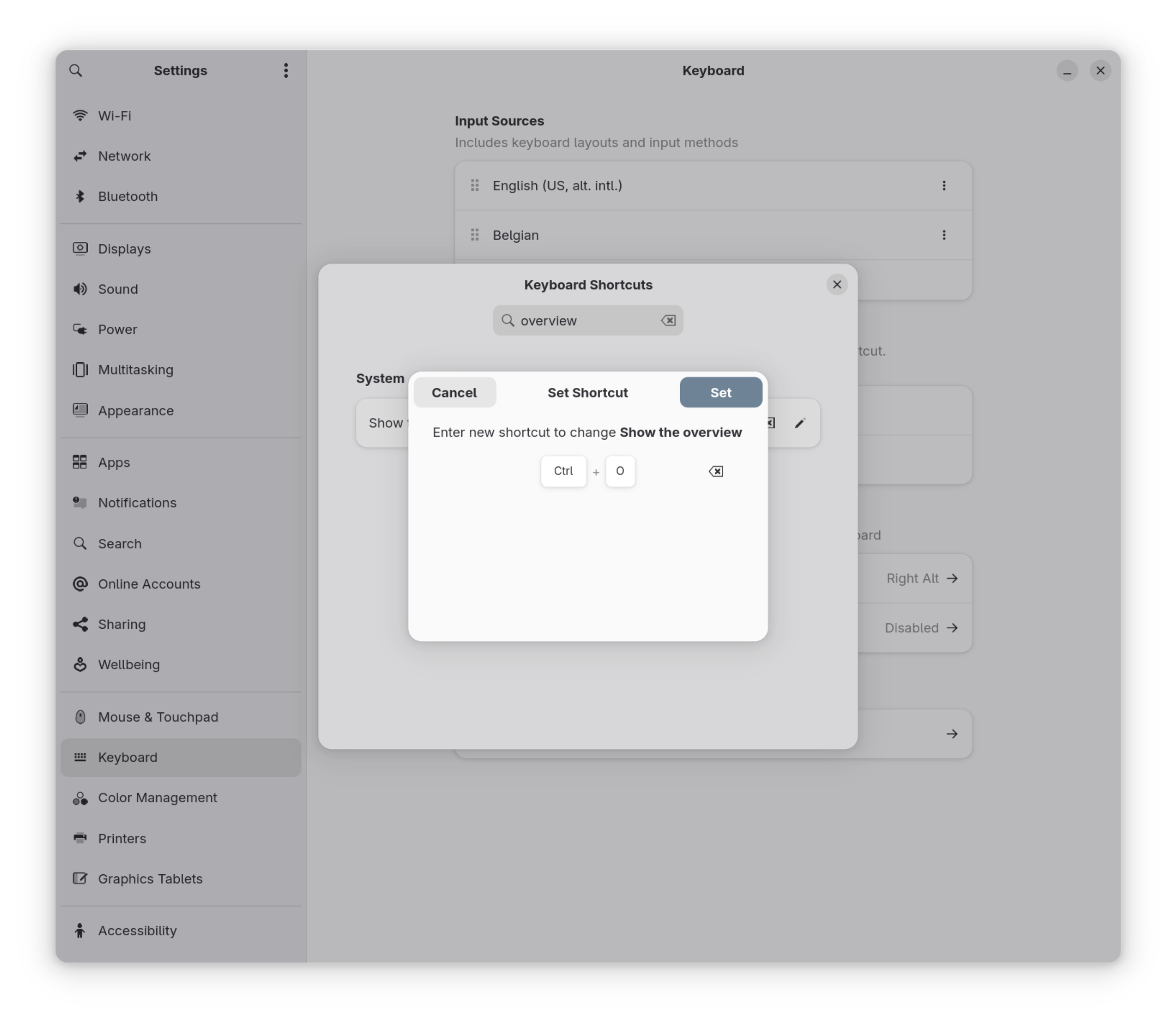
Note
Om te zorgen dat deze instellingen een reboot overleven, moet ook nog input-remapper eenmalig als service gestart worden: sudo systemctl enable --now input-remapper
Taadaaa! Hierna zal de middelste knop het app overzicht tonen.

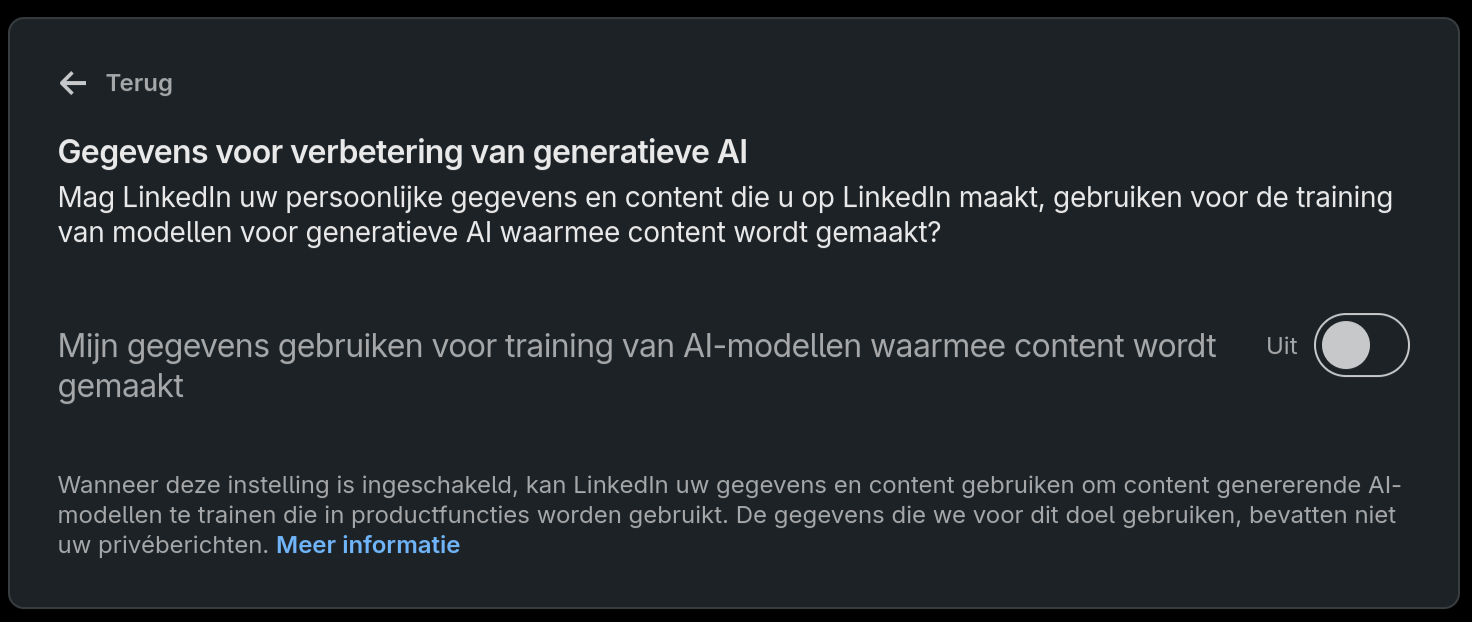
Deze week verscheen een artikel op security.nl waar erop in gegaan wordt dat LinkedIn is begonnen, of gaat beginnen, met gebruikers data te gebruiken om AI te trainen. Dit gaan ze ook doen met terug werkende kracht van informatie tot 2003. Hierbij kunnen vragen gesteld worden of dit volgens de AVG allemaal wel of niet mag. Het systeem van LinkedIn werkt met een opt-out, wat wil zeggen dat je zelf actie moet ondernemen om dit uit te schakelen.
Hieronder de stappen om dit te doen. Meldt je aan op je account bij LinkedIn. Ga hierna naar Instellingen / gegevensprivacy. Je ziet dan iets als het onderstaande:
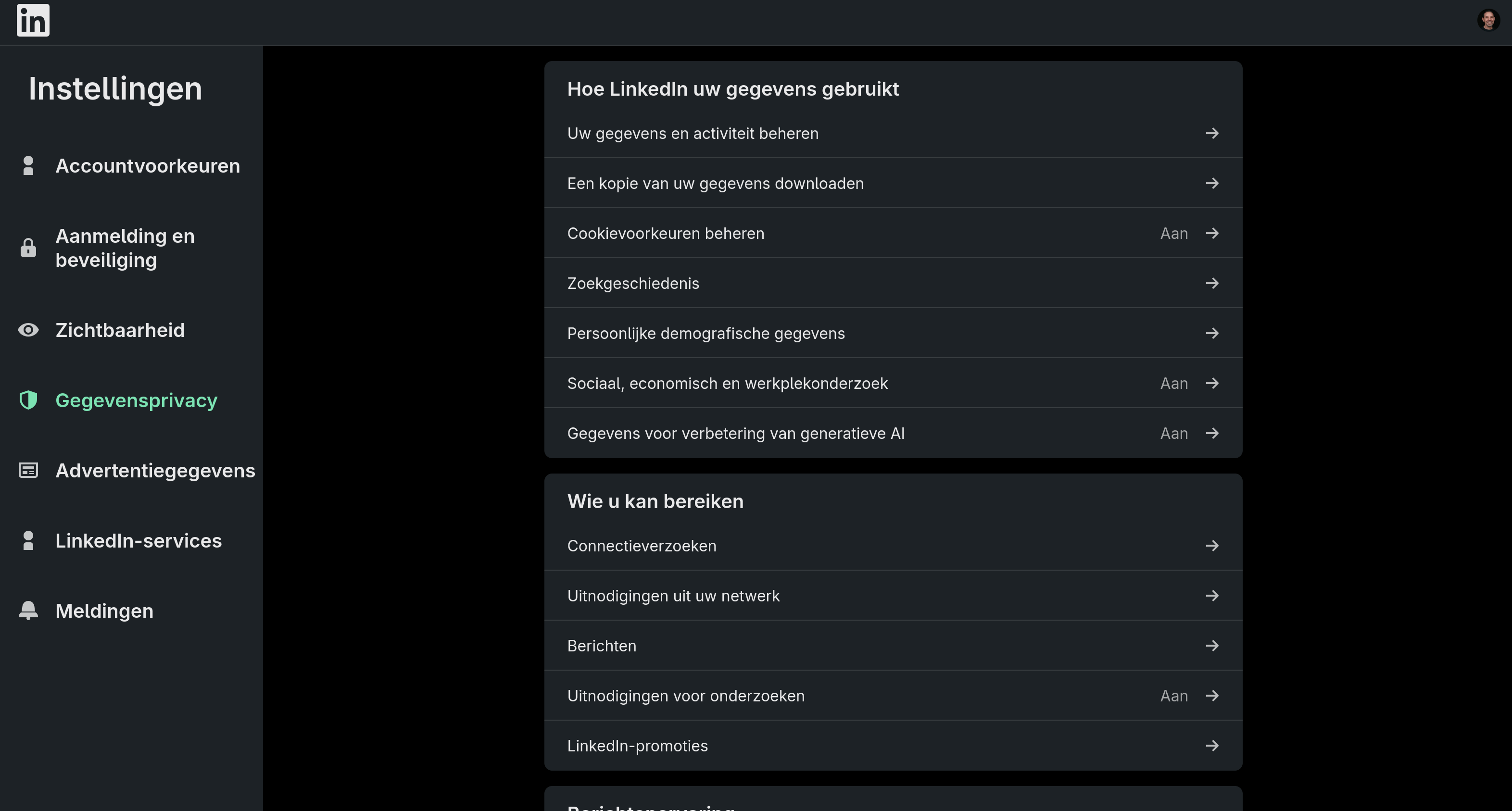
Hier is het kopje Gegevens voor verbetering van generatieve AI terug te vinden. Als je deze aanklikt krijg je een formulier te zien waar dit standaard ingeschakeld staat.
Door het wisselen van het IP van onze glasvezel, werkte het FQDN van de 3CX installatie niet meer. Deze is ingesteld via een my3cx.nl adres en deze wordt beheerd door 3CX. De free versie hier gebruikt wordt, heeft geen mogelijkheid om het IP te wisselen. In veel gevallen wordt een herinstallatie wordt hiervoor geadviseerd.
Nou is dat wat lastig, omdat de machine in een ander pand staat en momenteel wat lastig bereikbaar is. Daarnaast is dit een headless systeem. Het was even te overwegen om een VM omgeving op deze machine te zetten voor de toekomst, maar ook dit kost nog wat extra tijd en daarvoor moet ik alsnog bij de fysieke machine kunnen komen.
Intussen werkt de telefoon dus niet meer. De portal is via het nieuwe IP nummer wel bereikbaar, maar de app's gebruiken het FQDN. Na wat zoek werk vond ik wel het een en ander. De 3cx installatie is gebaseerd op Debian en er kan via ssh ingelogd worden. De 3cx webtool is overigens in .Net geschreven. Misschien andere delen ook wel, maar daar heb ik niet naar gekeken. In dit specifieke geval is de 3CX ISO gebruikt voor de installatie. Het is ook mogelijk om zelf Debian te installeren om vervolgens de installatie pakketten toe te voegen. Ook heb ik wel eens wat gezien over het draaien van 3CX in Docker, maar dat wordt volgens mij afgeraden door 3CX zelf.
Ik dacht dat het misschien mogelijk was om via dpkg-reconfigure de installatie wizard weer te starten. Dit heeft helaas geen effect verder. Hiermee zijn (denk ik) de configuratie bestanden hersteld op basis van de eerder gebruikte SetupConfig.xml. Ik ondekte ook nog dat via het onderstaande commando de web installatie wizard gestart kan worden:
/usr/lib/3cxpbx/PbxWebConfigTool -p /usr/share/3cxpbx/webconfig -nobrowser -port 5016
3CX zet behoorlijk strikt de firewall op het systeem, dus de gebruikt poort moet nog wel even open gezet worden. Maar ook dit commando heeft niet het gewenste effect omdat de services van 3CX nog draaien en dan zijn poorten in gebruik enzo.
Hierna vond ik het onderstaande commando ergens in een blog:
/usr/sbin/3CXWizard --cleanup
Via deze route worden alle services stop gezet en wordt de wizard weer gestart, zoals bij de initiële installatie. Hiermee kan je dan ook een schone installatie maken. Als je hierna de backup weer terug zet, is alles weer hersteld als daarvoor, behalve dat hij nu het nieuwe IP nummer gebruikt.
De stappen om te nemen om het IP nummer te herstellen:
3cxWizard met de --cleanup optie op de machine via de terminal.SetupConfig.xml bestand. Mocht je de originele nog hebben van de eerdere installatie, dan werkt dit vermoedelijk ook./var/lib/3cxpbx/Instance1/Data/Backups.De conclusie is dan ook dat 3CX met de free versie je een aantal features afhoud, wat hun goed recht is natuurlijk. Maar het systeem is wel zodanig opgezet dat het installeren en herstellen van een installatie heel simpel werkt.
In mijn zoektocht voor een imap omgeving om berichten te archiveren was mijn eerste plan om een Debian of Ubuntu omgeving te gebruiken. Ik kwam er al snel achter dat er niet heel veel documentatie over een eenvoudige opzet te vinden was. Toen liep ik tegen een Dovecot eigen docker implementatie aan.
De opzet van de container is wel wat simpeler dan de Debian of Ubuntu versie. Maar het lijkt er wel op dat alles erin zit wat nodig is. Inmiddels is versie 2.4.1 van de container te verkrijgen. Maar ja, hoe nu verder?
De basis setup van de container verwacht een wachtwoord via environment variabelen voor een gebruiker en de dovecot admin:
USER_PASSWORD=
DOVEADM_PASSWORD=
"Een wachtwoord voor één gebruiker?". Het blijkt dat de initiële setup zo gemaakt is dat hij elke gebruikersnaam accepteert en daarvoor een mailbox maakt, als dit wachtwoord wordt gebruikt. Op zich handig voor test omgevingen of zo, maar niet wat ik momenteel zoek. Ik wil voorlopig een basis opzet hebben, waarbij eventueel meerdere gebruikers aangemaakt kunnen worden. met een eigen wachtwoord. Dit wachtwoord en de opgeslagen mail moeten geëncrypt zijn. Hierbij ga ik alleen IMAP met SSL gebruiken. Voor het SSL certificaat wil ik letsencrypt gebruiken.
Ik heb via Dehydrated en Nginx een certificaat voor mijn domeinnaam aangemaakt. De container verwacht dat de certificaten als /etc/dovecot/ssl/tls.crt en /etc/dovecot/ssl/tls.key beschikbaar zijn. Voor de .crt gebruik ik fullchain.pem en voor de .key het privkey.pem certificaat. Deze worden via een volume mapping toegewezen.
De opgeslagen mail wil ik ook buiten de container opslaan. Standaard worden de mailboxen onder /srv/vmail aangemaakt.
services:
dovecot:
image: dovecot/dovecot:latest
restart: always
ports:
- 0.0.0.0:993:31993
volumes:
- "${DOCKER_DATAPATH}/certs/fullchain.pem:/etc/dovecot/ssl/tls.crt:ro"
- "${DOCKER_DATAPATH}/certs/privkey.pem:/etc/dovecot/ssl/tls.key:ro"
- "${DOCKER_DATAPATH}/vmail:/srv/vmail"
Voor het totale plaatje zijn er nog 3 mappings nodig. Ik pas de basis configuratie niet aan van de container, maar voeg alleen toe. Voor de gebruikers wordt en een users bestand (passwd-file) gebruikt, dat een zowel de gebruiker als het wachtwoord bevat, maar ook een paar extra lege velden.
Voor de aanvullende configuratie wordt een 10-auth.conf bestand aangemaakt in de conf.d map. Bij het opstarten wordt elke .conf bestand in deze map meegenomen.
Aanvullend kan ik alvast verklappen dat certificaten voor het encrypten van de bestanden in de map /etc/dovecot/mail-crypt terecht gaan komen"
- "${DOCKER_DATAPATH}/users:/etc/dovecot/users:ro"
- "${DOCKER_DATAPATH}/10-auth.conf:/etc/dovecot/conf.d/10-auth.conf:ro"
- "${DOCKER_DATAPATH}/dovecot-mail-crypt:/etc/dovecot/mail-crypt:ro"
Tijdens het testen heb ik Thunderbird gebruikt. Hierdoor liep ik al snel tegen een paar problemen aan. Het eerste probleem was, wanneer ik een mailtje in de mailbox sleepte, werd de verbinding verbroken met de melding dat er teveel ongeldige commando's verstuurd werden:
dovecot-1 | May 05 07:55:06 imap(myarchive)<21><t9Qz0F40vPW8Wgp1>: Info: Disconnected: Too many invalid IMAP commands. in=1677 out=2637 deleted=0 expunged=0 trashed=0 hdr_count=0 hdr_bytes=0 body_count=0 body_bytes=0
Na een behoorlijke wat zoektijd, kwam ik in een github ticket tegen, dat een experimentele extentie het probleem zou kunnen zijn. Via mail_utf8_extensions=no kan deze worden uitgeschakeld en werkt Thunderbird in eens wel zoals verwacht.
Het tweede probleem had iets met de standaard mappen te maken. Na deze uit de Ubuntu configuratie over genomen te hebben (zie namespace inbox {...) werkte de mailbox in eens zoals verwacht.
Zo ben ik tot de volgende opzet van 10-auth.conf gekomen:
# Use for debugging
# mail_debug=yes
# auth_verbose=yes
# auth_debug=yes
# auth_debug_passwords=yes
# mail_debug=yes
# Fix for Thunderbird
mail_utf8_extensions=no
# Authorization
auth_verbose_passwords=plain
auth_mechanisms = plain login
# removed: digest-md5 cram-md5
# Passdb configuration
passdb passwd-file {
driver = passwd-file
passwd_file_path = /etc/dovecot/users
}
# Userdb configuration
userdb passwd-file {
driver = passwd-file
passwd_file_path = /etc/dovecot/users
}
# Default folders
namespace inbox {
inbox = yes
mailbox Trash {
special_use = \Trash
auto = subscribe
}
# These mailboxes are widely used and could perhaps be created automatically:
mailbox Drafts {
special_use = \Drafts
}
mailbox Junk {
special_use = \Junk
}
# For \Sent mailboxes there are two widely used names. We'll mark both of
# them as \Sent. User typically deletes one of them if duplicates are created.
mailbox Sent {
special_use = \Sent
}
mailbox "Sent Messages" {
special_use = \Sent
}
}
# Encryption of mails
mail_plugins {
mail_crypt = yes
}
crypt_global_public_key_file = /etc/dovecot/mail-crypt/ecpubkey.pem
crypt_global_private_key main {
crypt_private_key_file = /etc/dovecot/mail-crypt/ecprivkey.pem
}
De certificaten voor het encrypten van de data moeten ook nog aangemaakt worden. Zorg ook dat de certificaten de juiste owner en rechten hebben binnen de container. De vmail gebruiker en groep hebben beide nummer 1000.
mkdir -p data/dovecot-mail-crypt
openssl ecparam -name prime256v1 -genkey | openssl pkey -out data/dovecot-mail-crypt/ecprivkey.pem
openssl pkey -in data/dovecot-mail-crypt/ecprivkey.pem -pubout -out data/dovecot-mail-crypt/ecpubkey.pem
chmod -Rf 600 data/dovecot-mail-crypt/*
chown -Rf 1000.1000 data/dovecot-mail-crypt
Om dit allemaal nou ook nog werkend te krijgen, moet er in ieder geval 1 gebruiker toegevoegd worden. Hiervoor kan de tool doveadm gebruikt worden. Misschien is het ook mogelijk om hiermee een gebruiker volledig toe te voegen aan het users bestand, maar zover heb ik niet gekeken. doveadm is in de container beschikbaar. Ik gebruik hier de encryptie SHA512-CRYPT om te zorgen dat het wachtwoord niet leesbaar is in de configuratie. Hier een voorbeeld:
docker compose exec dovecot doveadm pw -s SHA512-CRYPT
Enter new password:
Retype new password:
{SHA512-CRYPT}$6$RVEYzANS6v0a.kAB$.0lLSo2DaXwpi8E.iAClBoQu3GK36oWPCRp503ZlhDok3ixomdcMbiwURNScpxVlYHGD7UItfrlQz4tEMgaZ.
Deze laatste regel is het geëncrypte wachtwoord. Deze gaan we toevoegen aan het users bestand. Allereerst komt de gebruikersnaam in het bestand te staan. Hou er rekening mee dat deze in ieder geval geen : mag bevatten, omdat dit het scheidingsteken is tussen de velden. Deze wordt gevolgd door het wachtwoord. Het users bestandsformaat verwacht dan nog een aantal velden die we leeg gaan laten. Hierom voegen we :::::: toe aan de regel. Een voorbeeld is dan als volgt:
my-mail-user:{SHA512-CRYPT}$6$RVEYzANS6v0a.kAB$.0lLSo2DaXwpi8E.iAClBoQu3GK36oWPCRp503ZlhDok3ixomdcMbiwURNScpxVlYHGD7UItfrlQz4tEMgaZ.::::::
Belangrijk punt is dat dovecot herstart moet worden als dit bestand veranderd. Dit is een goed argument om een SQL server te gaan gebruiken hiervoor. Sqlite zou een prima oplossing kunnen zijn, maar dat is voor een andere keer. De container is zodanig kaal, dat ps of killall niet beschikbaar zijn. Een alternatief is dan ook om de container te herstarten. Maar dovecot heeft ook een herstart optie ingebouwd, wat het proces wat vloeiender maakt:
docker compose exec dovecot doveadm reload
Hierna zou je met elke IMAP applicatie moeten kunnen verbinden en mail naar deze mailbox moeten kunnen verplaatsen. Zorg wel voor een goede backup van de certificaten, anders zijn de e-mails niet meer te redden na een crash.
Online kwam ik een artikel tegen waarbij de auteur de stappen toont om XTTS-v2 te installeren. Wat me nogal vaak opvalt is dat dit soort blog posts verre van compleet zijn. Je zou bijna gaan denken dat het een vorm van clickbait is. Niet dat ik de auteur daarvan beschuldig hoor, integendeel. Hierbij dan ook mijn poging om het werkend te krijgen en wat meer diepgang te geven.
Ter info, ik gebruik in dit geval een Mac M1 machine. Onder Linux zullen de stap relatief hetzelfde zijn, vermoed ik.
In stap 1 wordt de repository van het project vanaf de git omgeving van huggingface gedownload.
git clone https://huggingface.co/coqui/XTTS-v2
De auteur gaat vervolgens de 'virtual environment' activeren, maar deze bestaat nog helemaal niet. Dus die gaan we aanmaken in de map van het project. Omdat ik in het verleden problemen ondervond met de hoogst geïnstalleerde versie van Python op mijn machine, kies ik ervoor om Python 3.10 te testen.
cd XTTS-v2/
python3.10 -m venv .
source ./bin/activate
Hierna zou de virtuale environment actief moeten zijn (bij mij verschijnt er (XTTS-v2) voor de command prompt. Waarom we dit doen? Op deze manier kunnen we het project scheiden van andere installaties op onze machine, zodat ze elkaar minder beïnvloeden.
De auteur wil vervolgens de requirements installeren. Dit kan je doen door alle benodigde pakketten in een bestandje te benoemen en dit met een commando te laten installeren. Hij heeft echter de volgorde verkeerd om staan. Dus we draaien het even om. We maken eerst het bestand requirements.txt aan. Ik heb een kleine wijziging erin gemaakt, wat veel vaker fout gaat bij dit soort blog posts en dat is het gebruik van PyTorch. Veelal wordt er verwezen naar een versie die niet meer bestaat. Op de PyTorch pagina is dezelfde versie wel te vinden, maar zonder de aanvulling op het versie nummer:
cat <<EOF > requirements.txt
absl-py==2.1.0
aiohappyeyeballs==2.4.3
aiohttp==3.11.2
aiosignal==1.3.1
annotated-types==0.7.0
anyascii==0.3.2
asttokens==2.4.1
attrs==24.2.0
audioread==3.0.1
babel==2.16.0
bangla==0.0.2
blinker==1.9.0
blis==0.7.11
bnnumerizer==0.0.2
bnunicodenormalizer==0.1.7
catalogue==2.0.10
certifi==2024.8.30
cffi==1.17.1
charset-normalizer==3.4.0
click==8.1.7
cloudpathlib==0.20.0
colorama==0.4.6
confection==0.1.5
contourpy==1.3.1
coqpit==0.0.17
cycler==0.12.1
cymem==2.0.8
Cython==3.0.11
dateparser==1.1.8
decorator==5.1.1
docopt==0.6.2
einops==0.8.0
encodec==0.1.1
executing==2.1.0
filelock==3.13.1
Flask==3.1.0
fonttools==4.55.0
frozenlist==1.5.0
fsspec==2024.2.0
g2pkk==0.1.2
grpcio==1.68.0
gruut==2.2.3
gruut-ipa==0.13.0
gruut_lang_de==2.0.1
gruut_lang_en==2.0.1
gruut_lang_es==2.0.1
gruut_lang_fr==2.0.2
hangul-romanize==0.1.0
huggingface-hub==0.26.2
idna==3.10
inflect==7.4.0
ipython==8.29.0
itsdangerous==2.2.0
jamo==0.4.1
jedi==0.19.2
jieba==0.42.1
Jinja2==3.1.3
joblib==1.4.2
jsonlines==1.2.0
kiwisolver==1.4.7
langcodes==3.4.1
language_data==1.2.0
lazy_loader==0.4
librosa==0.10.2.post1
llvmlite==0.43.0
marisa-trie==1.2.1
Markdown==3.7
markdown-it-py==3.0.0
MarkupSafe==2.1.5
matplotlib==3.9.2
matplotlib-inline==0.1.7
mdurl==0.1.2
more-itertools==10.5.0
mpmath==1.3.0
msgpack==1.1.0
multidict==6.1.0
murmurhash==1.0.10
networkx==2.8.8
nltk==3.9.1
num2words==0.5.13
numba==0.60.0
numpy==1.26.3
packaging==24.2
pandas==1.5.3
parso==0.8.4
pillow==10.2.0
platformdirs==4.3.6
pooch==1.8.2
preshed==3.0.9
prompt_toolkit==3.0.48
propcache==0.2.0
protobuf==5.28.3
psutil==6.1.0
pure_eval==0.2.3
pycparser==2.22
pydantic==2.9.2
pydantic_core==2.23.4
Pygments==2.18.0
pynndescent==0.5.13
pyparsing==3.2.0
pypinyin==0.53.0
pysbd==0.3.4
python-crfsuite==0.9.11
python-dateutil==2.9.0.post0
pytz==2024.2
PyYAML==6.0.2
regex==2024.11.6
requests==2.32.3
rich==13.9.4
safetensors==0.4.5
scikit-learn==1.5.2
scipy==1.14.1
shellingham==1.5.4
six==1.16.0
smart-open==7.0.5
soundfile==0.12.1
soxr==0.5.0.post1
spacy==3.7.5
spacy-legacy==3.0.12
spacy-loggers==1.0.5
srsly==2.4.8
stack-data==0.6.3
SudachiDict-core==20241021
SudachiPy==0.6.8
sympy==1.13.1
tensorboard==2.18.0
tensorboard-data-server==0.7.2
thinc==8.2.5
threadpoolctl==3.5.0
tokenizers==0.20.3
# Verwijderd vanwege versie problemen
# torch==2.5.1+cu124
# torchaudio==2.5.1+cu124
# torchvision==0.20.1+cu124
torch==2.5.1
torchaudio==2.5.1
torchvision==0.20.1
tqdm==4.67.0
trainer==0.0.36
traitlets==5.14.3
transformers==4.46.2
typeguard==4.4.1
typer==0.13.0
typing_extensions==4.12.2
tzdata==2024.2
tzlocal==5.2
umap-learn==0.5.7
Unidecode==1.3.8
urllib3==2.2.3
wasabi==1.1.3
wcwidth==0.2.13
weasel==0.4.1
Werkzeug==3.1.3
wrapt==1.16.0
yarl==1.17.1
EOF
Om deze vervolgens te gebruiken om de pakketten te installeren:
pip install -r requirements.txt
Als alles meezit wordt alles zonder meldingen geïnstalleerd. De oplossing van het versienummer werkt voor mij in ieder geval.
Vervolgens gaan we TTS installeren. De schrijver heeft het over dat deze installatie wel 40 minuten kan duren, maar 3 seconden later is hij klaar. Het is mij onduidelijk waarom hij dit schreef.
pip install TTS==0.22.0 --no-deps
In het vervolg wil hij PyTorch gaan installeren, maar dit is al gebeurd. Het lijkt wel of deze blog posts verkeerd om gepubliceerd is. En hierna houdt de post ook op. Wat hebben we nu bereikt? Nou, eigenlijk niet zoveel tot zo ver.
In de readme.md staat nog wat informatie van het project zelf. We nemen het eerste voorbeeld en passen hem een beetje aan. Aangezien het een variant is de voice cloning gebruikt, is er een audio sample nodig. Er staan een aantal voorbeelden in de samples map. Hiernaast is het voorbeeld wat verouderd. We passen het gpu=True aan naar tts.to("mps"). mps is de GPU acceleratie voor m1 processoren. Voor NVidea GPU's kan je cuda gebruiken.
cat <<EOF > test-1.py
from TTS.api import TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2")
tts.to("mps")
# generate speech by cloning a voice using default settings
tts.tts_to_file(text="It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
file_path="output.wav",
speaker_wav="./samples/en_sample.wav",
language="en")
EOF
python ./test-1.py
Na uitvoer loop ik tegen het volgende probleem aan:
NotImplementedError: Output channels > 65536 not supported at the MPS device. As a temporary fix, you can set the environment variable `PYTORCH_ENABLE_MPS_FALLBACK=1` to use the CPU as a fallback for this op. WARNING: this will be slower than running natively on MPS.
En hier begint dan ook meteen de ellende. Ik zou willen proberen of een nieuwere PyTorch versie dit oplost, maar dat kan niet zomaar. Na het aanpassen naar de laatste versie (2.7.0) moet ook sympy>=1.13.3 worden geïnstalleerd, wat weer leid tot het volgende:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tts 0.22.0 requires numpy==1.22.0; python_version <= "3.10", but you have numpy 1.26.3 which is incompatible.
Na het weer terug zetten van de requirements, probeer ik het voorstel wat in het log voorbij komt:
export PYTORCH_ENABLE_MPS_FALLBACK=1; python test-1.py
Dit lijkt geen effect te hebben. Als alternatief kunnen we tts.to("cpu") in het script gebruiken. En dit werkt wel! Maar ja, wel een stuk trager dan we zouden willen natuurlijk. Na het aanpassen naar cpu werkt het voorbeeld en hebben we een output.wav bestand.
Inmiddels geloof ik wel dat Engels behoorlijk goed uitgesproken kan worden met TTS systemen, maar Nederlands is nog vaak een probleem. Om dit te testen pas ik het script aan met een Nederlandse tekst en gebruik hierbij de engelse sample.
from TTS.api import TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2")
tts.to("cpu")
# generate speech by cloning a voice using default settings
tts.tts_to_file(text="Het is belangrijk dat het geluid duidelijk uitgesproken wordt, en daardoor verstaanbaar is.",
file_path="output.wav",
speaker_wav="./samples/en_sample.wav",
language="nl")
En het resultaat is erg goed! Een test met de Spaanse stem (een mannelijke stem) werkt wel, maar is niet geweldig. Ook de Franse sample levert niet echt geweldig resultaat. Het is overigens wel verstaanbaar. Als test heb ik online een audio sample gezocht, en met wat uitproberen komen er behoorlijk goede resultaten uit.
De snelheid op deze manier is helaas wel een puntje. Interessant zou zijn om het op een CUDA compatible systeem te testen, of te onderzoeken of en hoe dit direct met PyTorch te doen is.
Piper is een open source toolkit voor text-to-speech, waarbij de belofte wordt gedaan dat deze werkende op alleen CPU toch behoorlijk snel zou zijn. Het is hierbij ook mogelijk een eigen stem te trainen.
A fast, local neural text to speech system
De laatste 'release' op de Github page is van 14 november 2023, maar afgelopen maand zijn er nog commits toegevoegd. De bedoeling is om te kijken of we de laatste versie op macOS aan de praat kunnen krijgen.
Eerder liep ik tegen een aantal problemen aan. Het downloaden van de release kan via de github pagina. Als je vervolgens de .tar.gz hebt geopent en piper start (niet via de terminal), krijg je al gauw Apple could not verify “piper” is free of malware that may harm your Mac or compromise your privacy. Via de terminal krijg je een geheel andere melding te zien:
% ./piper
dyld[28586]: Library not loaded: @rpath/libespeak-ng.1.dylib
Referenced from: <65D01FDC-B71E-3786-8B0D-0BFEEC801633> /Users/peter/Downloads/piper/piper
Reason: tried: '/usr/local/lib/libespeak-ng.1.dylib' (no such file), '/usr/lib/libespeak-ng.1.dylib' (no such file, not in dyld cache)
zsh: abort ./piper
Wat de foutmelding aangeeft, is dat de libraries die piper wil gebruiken, niet op de juiste plek staan. Of in andere woorden, piper verwacht dat de libraries ergens staan (/usr/local/lib) wat niet het geval is. Daarnaast is de gevraagde library libespeak-ng.1.dylib niet aanwezig in het gedownloade tar-archief.
Piper is afhankelijk van het piper-phonemize project. Dit project zorgt voor het omzetten van de gevraagde tekst naar fonetische symbolen die nodig zijn voor het uitspreken. Ik dacht dat dit weer gebaseerd is op espeak-ng, maar omdat er een specifiek onderdeel hierin ontbreekt, hebben ze er een separaat project van gemaakt. Of iets in die richting.
In het gedownloade tar-archief is piper_phonemize ook aanwezig. Hiervoor geldt hetzelfde als voor het opstarten van piper:
% ./piper_phonemize
dyld[28668]: Library not loaded: @rpath/libpiper_phonemize.1.dylib
Referenced from: <3D98D201-8BC3-36CB-A5A6-1BF74A1CF7A8> /Users/peter/Downloads/piper/piper_phonemize
Reason: tried: '/usr/local/lib/libpiper_phonemize.1.dylib' (no such file), '/usr/lib/libpiper_phonemize.1.dylib' (no such file, not in dyld cache)
zsh: abort ./piper_phonemize
Ook deze library is niet aanwezig in het tar-archief. Als je piper_phonemize download vanaf de github pagina, is te zien dat de inhoud een stuk minder uitgekleed is. Sterker nog, alles wat tot nu toe geroepen wordt dat ontbreekt, is wel aanwezig in dit bestand. Echter krijgen we een zelfde soort foutmelding:
% cd ../piper-phonemize
peter@MacBookPro bin % ./piper_phonemize
dyld[28738]: Library not loaded: @rpath/libpiper_phonemize.1.dylib
Referenced from: <D5469D2B-CE4B-3598-B8B1-2374AA52AEF1> /Users/peter/Downloads/piper-phonemize/bin/piper_phonemize
Reason: tried: '/usr/local/lib/libpiper_phonemize.1.dylib' (no such file), '/usr/lib/libpiper_phonemize.1.dylib' (no such file, not in dyld cache)
zsh: abort ./piper_phonemize
Na een korte zoektocht blijkt dat deze programma's een directe verwijzing gebruiken naar de libraries (.dylib). Deze is hardcoded in de applicatie. Aangezien ik verder niet zoveel weet van applicaties compileren op macOS, moest ik het antwoord vinden in github reactie bij het piper project.
Via install_name_tool kan het pad van de library aangepast worden, in de executable:
#example, do not copy and paste this
sudo install_name_tool -change @rpath/libespeak-ng.1.dylib $PIPER_PHONEMIZE_DIR/lib/libespeak-ng.1.dylib $PIPER_DIR/piper
De persoon die de oplossing gepost heeft, heeft ook een script erbij geplaatst waarmee je de download en het corrigeren in 1 keer kan uitvoeren. Let wel op dat hij alles onder /usr/local installeert en dat is wat ik in ieder geval niet wil.
De conclusie is dat dus te downloaden release versie, niet out-of-the-box werkt, wat erg jammer is.
Terug naar de het doel. Buiten het kunnen downloaden, wil ik graag de laatste versie kunnen gebruiken. Er is een probleem met de Nederlandse stemmen en ik hoop te kunnen aantonen dat
De Github pagina van piper spreekt alleen maar over Linux desktop en 2 Raspberry PI variaties. De vraag is dan ook of er iets anders moet gebeuren voor macOS.
% git clone https://github.com/rhasspy/piper.git
% cd piper
% make all
..
cd build && ctest --config Release
CMake Error: Unknown argument: --config
CMake Error: Run 'ctest --help' for all supported options.
make: *** [all] Error 1
Hier liep ik eerder ook al eens tegenaan. ctest --config release lijkt op mijn machine niet te bestaan, maar ctest -C release wel. Na dit aangepast te hebben in de Makefile loopt het proces wel verder.
Dus de build gaat goed, maar vervolgens lopen we tegen hetzelfde probleem aan:
% ./install/piper
dyld[36638]: Library not loaded: @rpath/libespeak-ng.1.dylib
Referenced from: <CEAF996E-3687-34F0-BC89-7314F7904719> /Users/peter/Projects/poc/20250406-piper-from-source/piper/install/piper
Reason: no LC_RPATH's found
Het ziet er meteen naar uit dat de install directory niet alles bevat. Vervolgens heb ik hetzelfde gedaan voor piper_phomemize:
% git clone https://github.com/rhasspy/piper-phonemize pp
% cd pp
% make all
..
cd build && ctest --config Release
CMake Error: Unknown argument: --config
CMake Error: Run 'ctest --help' for all supported options.
make: *** [all] Error 1
nano Makefile
# pas aan naar `ctest -C release`
% make all
Als hij klaar is, staat in de install map een 4tal mappen, waaronder bin directory de piper_phonemize executable bevat. Echter is hiermee het probleem niet opgelost. We hebben dan wel de laatste versie van de code, maar nog steeds hetzelfde probleem.
Gelukkig ben ik niet de enige die hier tegenaan loopt. In Building for MacOS and iOS #14 wordt een zelfde probleem beschreven en wordt er gelukkig ook een oplossing genoemd. Een van de reacties geeft een oplossing gebruik te maken van de variabele DYLD_LIBRARY_PATH. Als ik het onderstaande probeer, dan werkt piper_phonemize!
cd pp
export DYLD_LIBRARY_PATH=`pwd`/install/lib/
./install/bin/piper_phonemize
Maar dan hebben we nog een oplossing voor piper nodig. Deze lijkt veel meer te ontbreken. Gelukkig kunnen we de combinatie van beide projecten hiervoor gebruiken. Ik ga er vanuit dat zowel de clone van piper en piper-phonemize, in dezelfde directory staan:
% ls -lFa
total 0
drwxr-xr-x 22 peter staff 704 Apr 6 13:36 piper/
drwxr-xr-x 22 peter staff 704 Apr 6 13:43 pp/
Ik gebruik het volgende om het aan te tonen. pwd zorgt ervoor dat de huidige directory wordt gebruikt als base pad. We zetten hierbij ook het pad voor de espeak data, omdat deze ook volledig in de piper-phonemize beschikbaar is:
PP="`pwd`/pp/install"
LIB="${PP}/lib"
ESPEAK_DATA="${PP}/share/espeak-ng-data"
PIPER_PATH="`pwd`/piper/install"
DYLD_LIBRARY_PATH="${LIB}" ; "${PIPER_PATH}/piper" --version --espeak_data "${ESPEAK_DATA}"
Uiteraard zal dit geen audio genereren, maar het versie nummer wordt wel getoond! Versie 1.2.0 is hiermee geïnstalleerd. Zorg dat het bovenste in de shell script verwerkt wordt en piper kan via de command line uitgevoerd worden.
Bij het uitkomen van Firefox versie 130 merkte ik op dat er een groep gebruikers begon te steigeren over een nieuwe feature die Mozilla heeft toegevoegd. Onder de Firefox Labs sectie staat het volgende geschreven:
Firefox now offers an easy way to try experimental features with a new Firefox Labs page in Settings.
- AI Chatbot feature lets you add the chatbot of your choice to the sidebar, for quick access as you browse.
- Picture-in-Picture auto-open experiment enables PiP on active videos when switching tabs.
De term AI is blijkbaar een reden om het product uit te sluiten. Misschien goed om even te kijken wat deze (optionele) feature die Mozilla heeft toegevoegd inhoud.
Allereerst, er zit dus geen AI in Firefox. Bij het inschakelen van de optie, wordt er gevraagd welke service je zou willen gebruiken. Dit is een externe service. Je hebt hierbij (op dit moment) de keuze uit de volgende opties:
Na het kiezen van 1 van de opties, verschijnt er een extra toolbar. Afhankelijke van welke dienst er gekozen is, zal er eerst ingelogd moeten worden. ChatGPT en HuggingChat lijken beide de gratis versie te bieden, terwijl je voor de rest eerst moet inloggen.
Okee, leuk, maar wat heb je eraan. Je kan in deze sidebar direct vragen stellen als je wilt. Dat is niet zo bijzonder. De andere feature is dat bij tekst selectie in je pagina, er een optie verschijnt:
![]()
Je kan op basis van de tekst selectie direct een prompt laten genereren met de taak die je aangeeft.
Een discussie die los ging, gaat over privacy. Er kan simpel gesteld worden dat er geen data gedeeld wordt met enige LLM / AI service, als deze niet ingeschakeld is, een tekst geselecteerd is en 1 van de bovenstaande acties uitgevoerd wordt.
Naar mijn idee is deze discussie los gebarsten uit onwetendheid, waarbij de gebruikers ook niet verder gekeken hebben wat het dan ook inhoud. Het is jammer dat een product als Firefox hierdoor negatief beoordeeld wordt, terwijl ze juist een hele duidelijke optionele feature hebben neergezet, zonder deze op te dringen. Persoonlijk zou ik graag zien dat er ook een optie voor een lokale installatie van bijvoorbeeld Ollama wordt toegevoegd, als we dan toch over privacy hebben.
Voor het lezen en tonen van RSS feeds, dacht ik dat het praktisch zou zijn om de inhoud van de link van de feed te tonen in een zogenaamde "readermode", zoals deze in veel browsers is ingebouwd. Na een kleine zoektocht lijkt het erop dat de reader mode van Safari gebaseerd is op de implementatie van Mozilla. En zo blijkt dat deze open-source is en op GitHub te vinden is: readability.
Dit klinkt natuurlijk als een interessante optie om te testen, maar ik gebruik .Net, en geen Node.js. Na wat zoekwerk kwam ik al snel meerdere implementaties tegen op nuget, waaronder SmartReader:
This library supports the .NET Standard 2.0. The core algorithm is a port of the Mozilla Readability library. The original library is stable and used in production inside Firefox. This way we can piggyback on the hard and well-tested work of Mozilla.
SmartReader also added some improvements on the original library, getting more and better metadata:
- site name
- an author and publication date
- the language
- the excerpt of the article
- the featured image
- a list of images found (it can optionally also download them and store as data URI)
- an estimate of the time needed to read the article
Some of these fields are now present in the original library.
It also allows to perform custom operations before and after extracting the article.
Het inzetten van SmartReader is nogal simpel. Voeg de package toe aan je project en laat SmartReader de pagina ophalen en beoordelen:
var article = SmartReader.Reader.ParseArticle("https://arstechnica.com/information-technology/2017/02/humans-must-become-cyborgs-to-survive-says-elon-musk/");
if(article.IsReadable)
{
Console.WriteLine($"Article title {article.Title}");
}
Er zijn nog diverse opties in te stellen, maar die sla ik voorlopig over. Voor het gebruik in mijn RSS reader, wil ik liever geen HTML hebben, maar Markdown tekst. Ik gebruik al langer de ReverseMarkdown packages, wat tot prima resultaten leid. Hier loop ik helaas wel tegen een probleem aan. Het blijkt dat de HTML soms veel tabs (of spaties) bevat, tussen een tekst node en een andere HTML node. Bijvoorbeeld een tekst gevolgd door een link. Maar ook een linefeed samen met tabs na een paragraph openings tag <p>. Hierbij worden de tabs niet verwijderd wat resulteert dat de markdown naar HTML deze tekst als <pre> formatteert.
Hierom is het verstandig om de HTML toch eerst nog wat op te schonen. AngleSharp is hier een prima oplossing voor. Ik heb ervoor gekozen om alle HTML element langs te lopen en de tekst in de textnode's op te ruimen:
public static void HtmlTextNodeTrim(INode node)
{
if (node is IElement elementNode)
{
foreach (var childNode in elementNode.ChildNodes)
{
HtmlTextNodeTrim(childNode);
}
}
else if (node is IText textNode)
{
var updatedText =
textNode.NodeValue = (textNode.Text ?? string.Empty).Trim() + " ";
}
}
Tijdens het schrijven van dit artikel bedenk ik me wel dat dit problemen kan opleveren met een <pre> of <code> tag. Dit is voor latere zorg. Door dit te combineren met het herformatteren van de HTML zonder indenting, komt er HTML uit die prima door ReverseMarkdown kan worden omgezet:
using System.IO;
using AngleSharp;
using AngleSharp.Dom;
using AngleSharp.Html.Dom;
using AngleSharp.Html.Parser;
protected virtual string GetReadable(string url)
{
try
{
var uri = new Uri(url);
var article = Reader.ParseArticle(uri.ToString());
if (!article.IsReadable)
return null;
// Get and sanitize HTML
var html = HtmlSanitizeHelper.SanitizeHtml(article.Content);
// Parse to markdown
return ReadabilityHelper.HtmlToMarkdown(html);
}
catch (Exception ex)
{
// ... do some logging
}
return null;
}
public class HtmlSanitizeHelper
{
public static string SanitizeHtml(string html)
{
var parser = new HtmlParser();
var document = parser.ParseDocument(html);
HtmlTextNodeTrim(document.Body);
return DocumentToHtml(document);
}
public static void HtmlTextNodeTrim(INode node)
{
if (node is IElement elementNode)
{
foreach (var childNode in elementNode.ChildNodes)
{
HtmlTextNodeTrim(childNode);
}
}
else if (node is IText textNode)
{
var updatedText =
textNode.NodeValue = (textNode.Text ?? string.Empty).Trim() + " ";
}
}
public static string DocumentToHtml(IHtmlDocument document)
{
using (var writer = new StringWriter())
{
document.ToHtml(writer);
return writer.ToString();
}
}
public static string HtmlToMarkdown(string html)
{
return new Converter(new Config()
{
UnknownTags = Config.UnknownTagsOption.Bypass,
GithubFlavored = true,
RemoveComments = true,
SmartHrefHandling = true,
TableWithoutHeaderRowHandling = Config.TableWithoutHeaderRowHandlingOption.Default
}).Convert(html);
}
}
Nog niet heel lang geleden is versie 8.4 van MySql uitgekomen. Hierin is een wijziging doorgevoerd m.b.t. de authenticatie. Voorheen kon met --default-authentication-plugin=mysql_native_password terug gevallen worden op de oudere (en vervallen) manier van de opslag van het wachtwoord. Na een update naar 8.4 start de server hierna niet meer op. Gelukkig hebben de ontwikkelaars hier een nog wel een optie voor toegevoegd.
Als vervanger kan nu --mysql-native-password=ON gebruik worden. Na aanpassen van de aanroep, werkt alles weer zoals vanouds:
services:
db8:
image: "mysql:8"
command: --mysql-native-password=ON --max_connections=999 --max-allowed-packet=96M --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --skip-log-bin
restart: always
cap_add:
- sys_nice
volumes:
- ${DOCKER_DATAPATH}/mysql8:/var/lib/mysql
Het gebruik van remote desktop (RDP) onder Windows werkt al jaren goed. Of het nou gaat om het delen van het fysieke scherm, of gebruik van (meerdere) virtuele bureaubladen. Dit werkte zowel voor home als pro gebruikers, met beperkingen goed. Helaas heeft Microsoft RDP uit de home editie gehaald. Wat macOS betreft is het RDP deel niet geweldig. MacOS biedt standaard de mogelijkheid om VNC te gebruiken om een scherm te delen. Hierbij wordt dan het fysieke scherm gedeeld. Dit werkt op zich prima met z'n beperkingen, mits de juiste viewer gebruikt wordt.
Via finder, of de "screen sharing" app, kan er een verbinding gemaakt worden met de host. Dit is wel mooi geïntegreerd hoor, maar een feature dat Windows (in sommige gevallen) heeft, is dat het bureaublad zich kan aanpassen aan de client die verbind. Wat de voorwaarde hiervoor zijn weet ik zo even niet. Om een remote desktop volwaardig te gebruiken als werkplek is dit wel noodzakelijk naar mijn mening. Om even wat kleine aanpassing te maken hoeft dat niet perse.
Tot mijn verbazing heeft de VNC client van macOS wel zo'n mogelijkheid. Dit was mij niet bekend en blijkt iets nieuws te zijn in macOS Sonoma. Als ik nu verbind met 2 machines die Sonoma 14.2.1 draaien, krijg ik de vraag wat voor een verbindings type ik wil gebruiken.
Als ik hierbij kies voor "High performance", komt er een extra optie beschikbaar. In de toolbar van het venster zijn de volgende opties te zien:
De 2de optie van links is "dynamic resolution". Als ik deze aanzet en het scherm bijvoorbeeld op full-screen zet, wordt de resolutie van het bureaublad net zo groot als mijn scherm. Dat werkt echt een stuk beter! Maar ja, dan komen we bij het punt dat dit alleen vanaf een macOS als client werkt.
Het zou mooi zijn als dit van een iPad, of wat voor een device dan ook, ook werkt. Helaas is dat niet zo. iPadOS heeft geen ingebouwde VNC viewer. Hiervoor kan bijvoorbeeld de app Jump gebruikt worden. Jump schaalt het scherm niet mee, waardoor het remote werken niet echt handig is. Een los toetsenbord maakt het gebruik al wel wat beter overigens. Jump biedt nog wel een andere optie, namelijk Jump Desktop Connect. Dit is een tool die op de remote machine geïnstalleerd kan worden. Hierna moet je even inloggen met een account. Als je vervolgens de Jump client met hetzelfde account inlogt, dan zal de remote machine verschijnen in Jump en kan je heel makkelijk de machine overnemen. Jump Desktop Connect belooft met een "fluid" optie dat de remote desktop de grote van het iPad scherm aanneemt. Dit leek bij mij niet te werken, maar mogelijk moet ik nog wat instellen daarvoor.
Ik gebruik Parallels om Windows in een VM te kunnen draaien. Parallels heeft ook nog een tool Parallel Access genaamd. Dit werkt hetzelfde als bij Jump Desktop Connect. Installeer de client tool en de app en je kan de machine met een druk op de knop overnemen. Ook hierbij geldt dat je de huidige resolutie overneemt, waardoor het scherm nogal onhandig is op een iPad. Soms helpt het om de resolutie van de client aan te passen, maar het scherm matcht nooit met de vormfactor van de iPad.
Er bestaat ook nog iets als Apple Remote Desktop, maar dit heb ik nog niet geprobeerd. Behalve dat het een betaalde app is, moet je hiervoor ook client tools installeren, zover ik weet. Dat is verder niet erg, als het vervolgens een goede desktop ervaring geeft. Deze ga ik zeker ook nog even proberen.
Misschien heb ik de juiste opties nog niet gevonden, maar het is jammer dat er geen uniforme oplossing binnen het Apple ecosysteem is, om remote de machines te besturen. Dit zou idealiter via iets met iCloud kunnen lopen.
Zou het niet handig zijn om LLM's te kunnen starten alsof het Docker images zijn? Dat was het idee dat de ontwikkelaars van Ollama hadden. Ollama is een tool, waarmee een groot aantal LLM's automatisch gedownload kunnen worden. Hierna kan er via de ollama cli gecommuniceerd worden met deze LLM's en er wordt ook nog een api mee geleverd zodat er tegenaan geprogrammeerd kan worden. Allemaal super handig en Ollama handelt al het moeilijke gedoe af.
Momenteel is Ollama alleen voor Linux en macOS beschikbaar, maar kan via WSL2 ook onder Windows gedraaid worden. Een GPU is hierbij wel aan te bevelen. Een M1 (of hoger) processor wordt hierbij ook ondersteund.
Na het installeren van Ollama is het simpel 1 van de LLM's te starten:
% ollama run llama2
>>> hoeveel is 1 + 1?
The answer to 1 + 1 is 2.
Grappig genoeg heeft Llama2 de neiging (voor mij) om altijd in het engels te antwoorden. Naast Llama 2 (er zijn ook verschillende grote variaties) zijn er nog diverse andere, zoals ook OpenChat en CodeLlama. Elke LLM heeft zo z'n voor en tegens. Let trouwens ook even op de hoeveelheid geheugen die beschikbaar is in je systeem, dit bepaald welke grote LLM je nog fatsoenlijk kan draaien op je machine.
Via ollama pull {LLM} kunnen de LLM's gedownload worden. ollama list maakt een mooi lijstje van de gedownloade LLM's beschikbaar en ollama rm {LLM} kunnen ze verwijderd worden. Hiernaast is het ook mogelijk om je 'eigen' image te maken. Net zoals via een dockerfile kunnen er vooringestelde instructies geschreven worden, waarna er een eigen image opgezet kan worden. Hiermee kan je de LLM van je keuze alvast tweaken voor het gebruik dat je wenst. Zo kan bijvoorbeeld de system prompt en de temperature instellen. Via deze methode kan je ook versies van je eigen LLM beheren.
Nog een interessante optie, is het combineren van Ollama met Open Interpreter. Deze laatste is een code hulp tool, die eventueel via de api van ChatGPT je code kan schrijven en ook uitvoeren. Het wordt hierbij nog extra interessant als dit allemaal lokaal kan draaien. Met deze combinatie kan dat:
% ollama pull codellama
% interpreter --model "ollama/codellama:latest" --api_base http://localhost:11434
Wat de kwaliteit van de gegeven antwoorden is, moet ik zelf ook nog ervaren, maar het scheelt in ieder geval in de kosten en is direct toegankelijk via de Command-line.
Afgelopen week is de nieuwe .Net 8 officieel gereleased. Deze versie zou bomvol met verbeteringen zitten die vooral de snelheid nog meer gaat verhogen. Hoe dan ook, ik vind het een belangrijk speerpunt om de software altijd up-to-date te houden.
Dotnet heeft een aardige feature, dat er meerdere variaties van de SDK's geïnstalleerd kunnen zijn. Dit is ook noodzakelijk om zowel .Net 6 en 7 applicaties door elkaar te kunnen gebruiken. Via dotnet --list-sdks krijg je snel te zien welke geïnstalleerd zijn.
Dotnet heb ik via brewgeïnstalleerd. Wat me al eerder opviel bij brew, is dat hij simpelweg altijd de laatste versie installeert van wat dan ook. Zo heb ik spontaan de nieuwe Reaper ontvangen en een poos terug de nieuwe Guitar Pro, waar ik beide geen licentie voor had. Voor dotnet-sdk geldt hiervoor hetzelfde. Bij het installeren van versie 8, worden alle eerdere geïnstalleerde versies verwijderd. Je krijgt dan iets als dit te zien:
You must install or update .NET to run this application.
Architecture: arm64
Framework: 'Microsoft.NETCore.App', version '7.0.0' (arm64)
.NET location: /usr/local/share/dotnet/
The following frameworks were found:
8.0.0 at [/usr/local/share/dotnet/shared/Microsoft.NETCore.App]
Learn more:
https://aka.ms/dotnet/app-launch-failed
To install missing framework, download:
https://aka.ms/dotnet-core-applaunch?framework=Microsoft.NETCore.App&framework_version=7.0.0&arch=arm64&rid=osx-arm64&os=osx.14
Process finished with exit code 150.
Een mogelijke oplossing is deze niet via brew toe te voegen, maar de officiële installatie van Microsoft. Maar er is ook een alternatief: homebrew-dotnet-sdk-versions.
Deze GitHub bevat een 'tap' om verschillende versies parallel te installeren. En het is heel simpel:
brew tap isen-ng/dotnet-sdk-versions
brew install --cask <version>
dotnet --list-sdks
Bij <version> kan je bijvoorbeeld kiezen voor dotnet-sdk8-0-100 en dotnet-sdk7-0-400. Als je hierna dotnet --list-sdks uitvoert krijg je wat je eigenlijk al eerder verwacht had:
% dotnet --list-sdks
7.0.404 [/usr/local/share/dotnet/sdk]
8.0.100 [/usr/local/share/dotnet/sdk]
.Net heeft een feature die het gebruik van nuget packages wat kan vereenvoudigen. De optie waar het om gaat heet ManagePackageVersionsCentrally en kan ingezet worden om de versies van de gebruikte pakketten centraal te registeren. Mogelijk dat deze optie voor mij het probleem oplost, dat ik niet in 1x alle pakketten in mijn solution kan upgraden. Soms heeft het meerdere pogingen nodig, of soms worden een aantal packageReferences simpelweg niet geupdate, wat tot rare effecten kan leiden.
ManagePackageVersionsCentrally is een optie die toegevoegd kan worden aan het bestand Directory.Packages.props. Dit bestand bestaat niet standaard en kan handmatig toegevoegd worden. In het geval van Rider heb ik nog geen optie gevonden om dit vanuit de IDE te doen, maar met de hand is het niet veel meer werkt.
Start hiervoor je favoriete teksteditor op en maak een bestaand aan met de volgende inhoud:
<Project>
<PropertyGroup>
<ManagePackageVersionsCentrally>true</ManagePackageVersionsCentrally>
</PropertyGroup>
</Project>
Hierin is de optie alvast ingeschakeld. Sla vervolgens dit bestand op in de root van de solution als Directory.Packages.props. Je kan deze eventueel ook op een ander niveau van de solution neerzetten, dan geldt het voor alles wat eronder valt.
Voor de handigheid heb ik in de solution ook nog een solution folder "Solution Items" aangemaakt. Soms bestaat deze al, dus dubbel zou ik hem niet proberen aan te maken. Vervolgens heb ik het bestand hieraan toegevoegd, zodat je hem makkelijk kan aanmaken.
Kopieer vervolgens de <ItemGroup> met de <PackageReference> vanuit 1 (of meerdere) van de projecten (.csproj file) hier naar toe. Dit inclusief het versienummer. Wat dit nu doet, is dat deze packages aan alle projecten worden toegewezen. Dat is natuurlijk niet de bedoeling. Verander daarom PackageReference naar PackageVersion. Nu definieerd dit de gebruikte versie van de package, voor de plekken waar om dit package gevraagd wordt. Let wel dat je het versie attribute in de .csproj verwijderd. Doe je dat niet, dan werkt het als een override.
Nog een punt waar ik tegenaan liep. Ik gebruik regelmatig submodules met git. Als er nu een globale Directory.Packages.props toegevoegd wordt, geldt dit ook voor deze submodules. Tevens kunnen projecten die in de IDE unloaded zijn wel effect hebben bij een dotnet restore. Als deze projecten wel een version attribute bevatten, treed de error NU1009 op. Dit is op te lossen door alle projecten aan te passen, maar dat kan niet altijd, of door <WarningsNotAsErrors>NU1009</WarningsNotAsErrors> toe te voegen aan de projecten.
Update: hoewel dit concept heel interessant is, werkt het alleen goed als alle projecten hierop ingesteld zijn. Bij gebruik van submodules kan het voorkomen dat niet alle projecten aangepast zijn, wat leid tot meldingen als " error NU1008: Projects that use central package version management should not define the version on the PackageReference items...". Het lijkt erop dat deze niet te onderdrukken zijn tot nu toe.
Momenteel als je zoekt naar het instellen van een disk quota voor een docker volume, via docker compose, kom ik tot nu toe alleen uit op een tmpfs. Zo'n volume is niet persistent, waardoor bij een herstart alle data weg is. Handig voor tempfiles, maar verder eigenlijk niet.
De enige oplossing die ik tot nu gevonden heb, is het gebruik van een disk image. Dit lijkt goed te werken. De image wordt namelijk via mount aan het locale filesystem geknoopt. Hierdoor kan je ook makkelijk bij de bestanden komen, voor bijvoorbeeld de backup.
Stap voor stap:
dd if=/dev/zero of="./cms_data.img" bs=5G count=1
mkfs.ext4 "./cms_data.img"
/etc/fstab bij opstart mounten. Uiteraard is het handig om dit eerst te testen:mkdir cms_volume
mount ./cms_data.img ./cms_volume
ls cms_volume/
umount ./cms_volume
als dit werkt, dan voeg ik hem toe aan fstab (Let op dat de directory waar deze gemount wordt moet bestaan).
{pad naar compose}/data/cms_data.img {pad naar compose}/data/cms_volume ext4 rw,relatime 0 0
services:
cms:
env_file:
- ./docker-compose.env
...
volumes:
- ${DOCKER_DATAPATH}/cms_volume:/opt/data
Meer en meer AI tools schieten als paddestoelen uit de grond. Naast dat het al een tijdje een mooi mode woord geworden is, zijn er ook echt hele interessante tools beschikbaar gekomen, waarvan sommige gratis te gebruiken zijn. Hieronder een klein lijstje van interessante tools:
Om het leven van gebruikers makkelijk te maken worden er nogal wat templates bedacht. Zo liep ik een keer tegen de bash template onderaan deze pagina aan (dit is een iets aangepaste versie), waarvan ik niet meer weet van wie en hoe deze heet, helaas. Na deze template veelvoudig toegepast te hebben liep ik nu toch tot een tekortkoming aan.
Uit betrouwbare bron kan ik verklappen dat het gebruiken van spaties in paden nogal tot onverwachte resultaten kunnen leiden, als hier niet goed mee om gegaan wordt. Helaas was ik niet zo verstandig geweest om de standaard naam van een extern medium aan te passen, waardoor ik overal nu rekening moet houden met deze spaties.
De originele template wordt basename gebruikt om de naam van het huidige script te bepalen:
__base="$(basename ${__file} .sh)"
Als er spaties voorkomen in deze regel, dan zal basename dit als verschillend parameters zien en hierbij meerdere regels als output geven. Dit is op meerdere manier op te lossen:
Ik heb hierbij gekozen voor de \s methode:
#!/bin/bash
# Set magic variables for current file & dir
__dir="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
__file="${__dir}/$(basename "${BASH_SOURCE[0]}")"
__base="$(basename ${__file// /\s} .sh)"
__root="$(cd "$(dirname "${__dir}")" && pwd)" # <-- change this as it depends on your app
__base bevat hierna maar 1 resultaat.
Eén van de manier om de veiligheid van inloggen op websites te versterken is het gebruik van 2Fa, of te wel, two-factor authentication of multi-factor authentication. In de praktijk werkt dat als volgt: je logt in met je gebruikersnaam en wachtwoord, en moet vervolgens nog een extra code invullen die bijvoorbeeld gegenereerd wordt van uit een app op je telefoon. Deze code veranderd elke minuut en kan dus niet zomaar gegokt worden. Uiteraard zijn er verschillende variaties van dit concept beschikbaar.
Jaren terug kreeg ik een sleutelhanger waar elke minuut een nieuwe code op stond. Deze code had ik dan nodig om te kunnen inloggen. Intussen zijn deze (denk ik) vervangen voor gebruik van een app op iemand z'n telefoon. Google heeft bijvoorbeeld de Google Authenticator app, voor zowel IOS als Android en zo heeft Microsoft ook zijn eigen app. Microsoft pakt het hierbij ook meteen een stuk breder aan. Zo hoef je in sommige gevallen, nadat het ingesteld is naast, bij het inloggen op de Microsoft websites geen wachtwoord meer op te geven, maar moet je jezelf autoriseren met de app, door een code te bevestigen die zowel op het scherm als op de app getoond wordt. Erg handig.
Hiernaast gebruik ik nu een tijdje een Ubikey. Dit hardware sleuteltje kan je dan in combinatie met een app gebruiken om deze codes te genereren. De app kan zowel op je telefoon of op je desktop draaien. Via de telefoon gebruik je dan bijvoorbeeld NFC om de codes zichtbaar te krijgen, terwijl op de desktop plug je hem in een USB poort. Persoonlijk loop ik nu tegen het punt aan dat ik 2 afhankelijkheden nodig heb. Misschien wel extra veilig, maar als er iets met de Ubikey gebeurd heb ik voor mijn gevoel een te grote uitdaging. Morgen denk ik hier misschien weer anders over, maar dit is iets wat in mijn achterhoofd speelt.
Tot mijn grote verbazing liep ik tegen een artikel aan van Nikhil Vemu, waarin deze beweerd dat Apple dit (stiekem of gewoon niet heel erg bekend) al gewoon ingebouwd heeft. Zo stelt hij, dat je 2Fa direct op je telefoon ken gebruiken zonder wachtwoord. Het werkt als volgt:
En dan klaar. Maar ja, hoe werkt het dan? Eigenlijk kan het niet simpeler, tenminste, als je meer Apple producten gebruikt en iCloud synchronisatie hebt. Als ik nu inlog op die site, met het juiste gebruikers account, zal bij de vraag om de verificatie op te geven een dropdown getoond worden met de gebruikersnaam en "verification code for ...". Hierop klikkende wordt automatisch het nummer ingevoerd! En dit werkt op je iPhone op dezelfde manier. Inloggen is zo niet alleen veiliger, maar ook nog eens heel simpel zonder extra hulpmiddelen!
Afgelopen weken werd tijdens het DotNet Conference 2021 de nieuwste telg in de .Net familie geïntroduceerd door Microsoft. Veel nieuws was het niet, want het meeste was natuurlijk al lang bekend in de communities. Wel wordt er met .Net 6 de volgende stap in de toekomst gezet. Al het nieuws kan o.a. op YouTube bekeken worden, dus daar zal ik me verder niet over uitweiden.
Een stap naar de toekomst van Microsoft is een unified platform voor grafische applicaties, .Net Maui. Hoewel ze al eerder pogingen gedaan hebben om WinForms uit te bannen (de oudste manier van GUI applicaties maken in .Net, geloof ik), worden de GDI applicaties in Windows 10 en 11 nog steeds ondersteund. In Windows 10 is er zelfs een aardige upgrade aan deze libary gegeven om te zorgen dat deze applicaties enigszins goed getoond werden op schermen waarbij de desktop geschaalt wordt.
Een interessante stap vooruit wordt gemaakt met .Net 6 is System.Drawing(.Common). Waar dit vroeger de manier was om iets grafisch te ondernemen (GDI+), is nu de stap genomen om deze Library als "Windows Only" te bestempelen. Tot voorheen kon mono-libgdiplus van het Mono project gebruikt worden om op andere systemen toch gebruik te maken van System.Drawing. Het was hiermee zelfs mogelijk om sommige Windows Forms (GDI+) applicaties te gebruiken op Linux en MacOS. Overigens heb ik het daar nooit voor gebruikt, maar wel voor het gebruik van de Image en Bitmap classes. Een concreet voorbeeld is het decoderen van QR-Codes vanuit gescande PDF's. Mono-libgdiplus wordt overigens al langere tijd niet meer actief onderhouden.
Met de overstap naar .Net 6 werkt dit niet simpelweg niet meer als je geen Windows gebruikt. Nou zou je kunnen kiezen om delen van de code via .Net 5 laten draaien, maar in de toekomst gaat dit toch echt wel problemen opleveren. Dus maak ik liever de stap om het future-proof te maken.
Inmiddels zijn er meerdere alternatieven gemaakt voor System.Drawing. Het nadeel is dat dit nooit drop-in-replacements zijn, dus er is wel wat meer werk voor nodig. ImageSharp is zo'n project dat een volledige 'managed' 2D grafische tool wil bieden voor .Net
ImageSharp is a new, fully featured, fully managed, cross-platform, 2D graphics library. Designed to simplify image processing, ImageSharp brings you an incredibly powerful yet beautifully simple API.
ImageSharp is designed from the ground up to be flexible and extensible. The library provides API endpoints for common image processing operations and the building blocks to allow for the development of additional operations.
Built against .NET Standard 1.3, ImageSharp can be used in device, cloud, and embedded/IoT scenarios.
Één van de toepassingen waarvoor ik zo'n Library nodig heb, is het onttrekken van plaatjes vanuit PDF's. Deze PDF's zijn scans van A4 en A3 bladen via een multifunctionele printer. De PDF's worden geopend via ITextSharp. Hierbij kunnen alle objecten in een PDF terug gevonden worden, zo ook de plaatjes. Deze plaatjes zijn echter niet altijd direct te gebruiken, dus zullen ze omgezet moeten worden naar iets bruikbaars. Door ImageSharp te gebruiken wordt dit een stuk simpeler dan voorheen:
using System.IO;
using iTextSharp.text.pdf.parser;
using SixLabors.ImageSharp;
using SixLabors.ImageSharp.PixelFormats;
namespace WillowMedia.Common.Pdf.Reader
{
public static class PdfImageObjectExtensions
{
public static Image<Rgba32> GetDrawingImage(this PdfImageObject pdfImageObject)
{
var r = pdfImageObject.GetImageAsBytes();
if (r == null)
return null;
var image = Image.Load(new MemoryStream(r));
return image.CloneAs<Rgba32>();
}
}
}
Image.Load is de ImageSharp functie, die eenvoudig het PDF plaatje als image object omzet. Via CloneAs<Rbga32> krijg ik hierbij een voor mij bruikbaar object terug.
Maar wat heb je eraan als deze objecten door geen andere Library ondersteund worden? In mijn geval is dat niet het geval. ZXing.net snapt de Image object van ImageSharp niet direct, maar via het ZXing.Net.Bindings.ImageSharp Nuget package wordt deze wel ondersteund:
public IBarcodeReader<Image<Rgba32>> GetQrCodeBarcodeReader()
{
var reader = new ZXing.BarcodeReader<Image<Rgba32>>(CreateLuminanceSource);
reader.Options.PossibleFormats = new List<BarcodeFormat>() {
BarcodeFormat.QR_CODE
};
return reader;
}
private BaseLuminanceSource CreateLuminanceSource(Image<Rgba32> image)
{
return new ImageSharpLuminanceSource<Rgba32>(image);
}
ZXing.net kan hierdoor de plaatjes wel inspecteren en doorzoeken op barcodes. Dit binding project is nog wel in Beta, maar tot zover bekend goed inzetbaar.
.Net 6 neemt hiermee de eerste stappen om het verleden achter ons te laten. We kunnen niet simpelweg door blijven gaan om altijd compatible te blijven met het verleden. Dit zou slecht zijn voor innovatie. Windows zelf heeft dit al heel lang gedaan en uiteraard hoeven ze (en ook niet wenselijk) de ondersteuning niet direct te dumpen. Via een goed alternatief zou het simpel gemaakt moeten worden om over te stappen naar iets nieuws. Of dit .Net Maui zal zijn, moet nog blijken natuurlijk. Ik ben voorlopig weer geholpen.
In veel gevallen start ik MySql in Docker zo op, dat er een random root wachtwoord wordt aangemaakt. Dit is prima, mits je of het wachtwoord uit de logfile haalt. In het geval dat je deze niet hebt, kan je mogelijk in de problemen komen. Zo liep ik tegen het probleem aan dat binary logging aan stond en m'n schijfruimte vol begon te lopen.
Het gaat in dit geval om MySql 8, hoewel de methode voor een oudere installatie hetzelfde zal zijn, is de sql die uitgevoerd dient te worden wel anders. MySql kan opgestart worden met een initialisatie script, waarmee bijvoorbeeld het wachtwoord wordt aangepast.
We stoppen de container en starten deze weer op buiten het normale proces om. Of te wel, de container wordt gestart maar met bash als startup:
> docker-compose stop mysql
> docker-compose run mysql bash
Hierna zal je in de command prompt terecht komen. We maken een initialisatie script aan met de sql om het wachtwoord aan te passen:
> cat << 'EOF' > mysql-init.sql
ALTER USER 'root'@'localhost' IDENTIFIED BY 'super-secret-password';
FLUSH PRIVILEGES
Hierna starten we mysql op via mysqld_safe, met het script als parameter. Door & te gebruiken wacht de shell niet totdat de applicatie klaar is. Hij draait dus in de achtergrond:
> mysqld_safe --init-file=mysql-init.sql &
[1] 7
Logging to '/var/lib/mysql/b96a199271ba.err'.
2021-11-09T09:17:30.107776Z mysqld_safe Starting mysqld daemon with databases from /var/lib/mysql
Overigens lijkt het er wel op dat de shell wacht tot het programma klaar is, maar als je een enter geeft zal er een nieuwe regel met de command prompt getoond worden. Vervolgens wachten we heel even zodat mysql kan starten en het script kan starten. Hierna kunnen we testen of het gelukt is:
> mysql -u root -p"super-secret-password" -h localhost
Als alles gelukt is, zal je hierna inloggen met het nieuwe wachtwoord. We sluiten de container via control+d of exit, en starten deze weer normaal op. Hierna is het mogelijk om als root met het nieuwe wachtwoord in te loggen:
> docker-compose up -d
Aanvullend, om vervolgens de binary log te laten krimpen kan bijvoorbeeld de volgende sql uitgevoerd worden, als root:
PURGE BINARY LOGS BEFORE '2021-11-09'
In de mysql versie die ik later gebruikte, is er geen mysqld_safe commando meer. Dit heeft geloof ik te maken met de overstap naar systemd. Het alternatief hiervoor is om mysql te laten starten met een sql script die het wachtwoord reset. Bij het opstarten worden de scripts uitgevoerd als de root gebruiker. In de directory waar dockercompose.yml staat voer ik het volgende uit:
mkdir startup
cat << 'EOF' > startup/mysql-init.sql
UPDATE mysql.user SET authentication_string=null WHERE User='root';
flush privileges;
EOF
Voeg vervolgens een volume toe aan de dockercompose.yml file: - ./startup:/docker-entrypoint-initdb.d. Herstart hierna de container:
docker-compose restart mysql
Vervolgens kan je als root inloggen zonder wachtwoord. Vergeet niet om het script te verwijderen en het wachtwoord aan te passen
docker-compose exec mysql mysql -u root -p
Afgelopen periode is de langverwachte update van Selenium.WebDriver vrijgegeven. Inmiddels is hij alweer ge-update naar versie 4.0.1. In ieder geval een goed moment om alle testen weer eens onder de loop te nemen.
Waar ik voorheen Selenium zal in Docker liet draaien, met een Chrome instantie, heb ik er nu voor gekozen om de Selenium.WebDriver.ChromeDriver package te gebruiken. Een handigheid is dat deze packages zorgen voor de juiste browser instantie voor het OS waarop je draait. Zo kan ik deze packages net zo goed onder MacOS gebruiken, als onder Linux.
De code die ik hiervoor gebruikte is vooral gericht op de remoteDriver voor Selenium, maar nu wilde ik alles integreren. Dus Selenium, met Chrome (later ook nog andere browsers) waarbij het test project ook de website start en alles aan elkaar knoopt.
Dat klonk in ieder geval simpel zat. Of er nou een webHost.UseTestServer() wordt aangeschoten, of via ConfigureKestrel() de hele site 'publiek' beschikbaar wordt gemaakt is niet zo'n groot verschil. Hiervoor heb ik een nieuwe xunite project aangemaakt en alle projecten toegevoegd. Nog even het ChromeDriver extra toegevoegd en na wat aanpassingen starte de site netjes op. Een nieuwe test startup class, die de oorspronkelijke portal startup class override, zorgt voor een dummy database in Sqlite, waardoor er bij elke run een nette en schone database beschikbaar is.
Allemaal prima. Tot het punt, dat ik een action probeerde aan te roepen. Het blijkt na wat te proberen, dat de gestarte site alleen de static content herkend. De views zijn wel terug te vinden, maar totaal niet benaderbaar, laat staan dat er een api aan te roepen is. Ik heb gezocht in het feit of het ContentPath, of het WebRootPath het probleem was, of de dll wel beschikbaar waren etc etc, maar de oplossing was heel simpel...
Bij het maken van een nieuw xunit project wordt er een csproj file aangemaakt die begint met:
<Project Sdk="Microsoft.NET.Sdk">
Uiteraard heb ik hier verder totaal niet naar gekeken, maar naar het aanpassen van de sdk naar Microsoft.NET.Sdk.Web, starte de site volledig op:
<Project Sdk="Microsoft.NET.Sdk.Web">
Nadat de spanning van een bepaalde machine per ongeluk uitgevallen was, starte een aantal Docker services op deze machine niet meer op. Het gaat hier om een Ubuntu server, met Docker en Docker services, die op een ZFS pool geïnstalleerd zijn. Het blijkt al snel dat Docker niet gestart is, oftewel niet heeft kunnen opstarten. Bij een poging om docker met de hand te starten trad de volgende melding op:
# systemctl start docker
Job for docker.service failed because the control process exited with error code.
See "systemctl status docker.service" and "journalctl -xe" for details.
# docker ps
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
for details.
root@gitlab:~# journalctl -xe
...
Sep 20 12:55:28 gitlab dockerd[2582]: time="2021-09-20T12:55:28.711755440Z" level=error msg="No zfs dataset found for root" backingFS=extfs root=/mnt/pool/docker storage-driver=zfs
Sep 20 12:55:28 gitlab dockerd[2582]: failed to start daemon: error initializing graphdriver: prerequisites for driver not satisfied (wrong filesystem?)
...
De melding "No zfs dataset found for root" geeft een hint in de richting waar het fout loopt. In een gevonden blog wordt voorgesteld om Docker handmatig te starten, om zo extra informatie te krijgen over de foutmelding:
# dockerd -D
INFO[2021-09-20T17:21:01.568981520Z] Starting up
WARN[2021-09-20T17:21:01.569091174Z] Running experimental build
DEBU[2021-09-20T17:21:01.569723852Z] Listener created for HTTP on unix (/var/run/docker.sock)
DEBU[2021-09-20T17:21:01.569776503Z] Containerd not running, starting daemon managed containerd
...
ERRO[2021-09-20T17:21:01.761962993Z] No zfs dataset found for root backingFS=extfs root=/mnt/pool/docker storage-driver=zfs
...
failed to start daemon: error initializing graphdriver: prerequisites for driver not satisfied (wrong filesystem?)
Dit laat dezelfde foutmelding zien. Na een kleine zoektocht via Google, vond ik het volgende: zfs datasets won't get mounted after reboot #2256. Ondanks dat de oorzaak duidelijk anders is, kwamen er wel een paar goede tips naar voren. Zo stelt één schrijver dat het mounten niet gelukt:
# zfs list -o name,mountpoint,mounted
NAME MOUNTPOINT MOUNTED
pool /mnt/pool no
pool/docker /mnt/pool/docker no
...
pool/docker/1050d0e34ff06a3d93bc4da64f7ce7aa8c89b381d4f98068537860d196e1f52f legacy no
pool/docker/10fbd64a618bcbb8ae254047ee2d05a1523d9a8213003e36a38105a56faab6ae legacy no
...
pool/docker/ca07de0a801bb595c8bda47307bef9c56b76bf78a22b33fca0a433580c195303 legacy no
pool/docker/f74a870580cb88cb86851909d22c5482aa6a98294fe830302eca53670eb90379 legacy no
...
En dit blijkt in ons geval ook zo te zijn. O.a. "pool" en "pool/docker" geven "no" bij mounted. Let wel, dat een ls /mnt/pool of ls /mnt/pool/docker wel werkt. Het is alleen wel onduidelijk of het compleet is wat getoond wordt. De aanbevolen vervolg stap is het opnieuw mounten van deze 2 mount points:
# zfs mount -a
cannot mount '/mnt/pool': directory is not empty
cannot mount '/mnt/pool/docker': directory is not empty
Ook hierbij treed dezelfde melding op als bij de schrijver. Hierna ruimt de schrijver met een rm -rf ... de directory op, om vervolgens deze opnieuw te laten mounten. Dit is in ons geval niet verstandig. /mnt/pool/ is niet leeg, en mogelijk verwijderen we daarmee data die nog van belang is. Als alternatief probeer ik de directory te hernoemen om vervolgens dezelfde stappen te nemen:
# mv /mnt/pool /mnt/pool-old
# zfs mount -a
# zfs list -o name,mountpoint,mounted
NAME MOUNTPOINT MOUNTED
pool /mnt/pool yes
pool/docker /mnt/pool/docker yes
...
De pool's zijn weer terug! Vervolgens moet docker nog gestart worden. Dit doe ik door de machine te herstarten, om te kijken of alles weer netjes start.
Ondanks er vanuit het veld opgeroepen, om geen ZFS te gebruiken als filesystem, maar om het 'standaard' BTRFS in te zetten, kies ik er toch nog voor om ZFS in te zetten. Ubuntu 20.04 levert nu zelfs een experimentele optie om ZFS te gebruiken. Of dit iets zegt weet ik niet, maar gewenning is voor mij het simpele argument om dit in te zetten.
In het kader van een nood oplossing heb ik een tijdelijks backup machine opgetuigd, op basis van Ubuntu 20.04, met de keuze om ZFS te gebruiken. Waar ik voorheen meestal m'n backup script als root uitvoerde, heb ik er nu voor gekozen om een gebruiker automatisch te laten inloggen, zodat o.a. de Nextcloud client constant kan synchroniseren. Dit heeft als voordeel dat ik niet s'nacht de volledige Nextcloud omgeving naar de backup machine hoef te kopiëren. Het nadeel is natuurlijk dat er een desktop omgeving constant actief is.
In plaats van een script als root uit te voeren laat ik dan nu een script als deze gebruik uitvoeren. Dit script zorgt voor de nodige laatste kopieën van data. De bedoeling is dat aan het eind van het script, er een snapshot gemaakt wordt van deze data, zodat er terug in de tijd gelopen kan worden. Bij het installeren van het systeem, was ik al begonnen met een pool te maken voor de backup lokatie. Hiervoor moet wel eerst de naam van de pool worden achterhaald:
$ mount | grep backupusr
rpool/USERDATA/backupusr_60orxl on /home/backupusr type zfs (rw,relatime,xattr,posixacl)
De experimentele Ubuntu implementatie maakt blijkbaar diverse pools aan, voor diverse mappen. Zo ook voor de home directory. Hier kan je je eigen pool's aan toevoegen:
$ sudo zfs create rpool/USERDATA/backupusr_60orxl/backup
Hierna zal de map /home/backupusr/backup terug te vinden zijn. Echter, omdat we dit als root uitvoeren, is de map ook alleen toegankelijk voor root. Dat was natuurlijk niet helemaal de bedoeling, maar het is makkelijk op te lossen:
$ sudo chown backupusr.backupusr ~/backup
Ik zal verder niet op de details van het backup script in gaan, maar het is de bedoeling dat ongeacht de uitkomst van het script, er een snapshot wordt gemaakt met de datum van dat moment:
MOMENT=`date +"%y%m%d"`
SNAPSHOT="rpool/USERDATA/backupusr/backup@${MOMENT}"
zfs snapshot "${SNAPSHOT}"
Dit script draait dus als de backupusr, en zo blijkt dat deze geen snapshots mag maken. Na een kleine zoektocht kwam ik erachter dat zfs een zfs allow optie heeft. Hiermee kan je o.a. aan een gebruiker één of meerdere permissies toekennen. De permissies voeg ik in dit geval toe aan de specifieke pool:
sudo zfs allow -u backupusr snapshot,destroy,rollback,diff rpool/USERDATA/backupusr_60orxl/backup
Hierna is het mogelijk om als de backupusr zfs snapshot ... uit te voeren.
Met de komst van DotNet Core 3.1 is er ook nieuwe leven ingeblazen in het kunnen maken van achtergrond services, a.k.a. Windows Services, maar niet gelimiteerd aan Windows! Sterker nog, Microsoft leverde meteen ook ondersteuning voor systemd (Linux) mee. Nou is er niks specifieks om launchd te ondersteunen, maar ook zonder is het simpel om een DotNet programma als achtergrond service te laten draaien.
Zo'n (achtergrond) service is niet meer dan een console applicatie. De integratie met systemd en windows services zorgt er voor dat de applicatie bepaalde features van deze systemen herkend. Maar dit is niet per definitie noodzakelijk. Launchd kan hierbij een console applicatie starten en in de gaten houden of deze nog actief is. Zo niet, dan herstart hij deze optioneel. De Launchd services worden beschreven in een plist xml. Dit is een simpel formaat in de vorm van een dictionary (key en values). Hieronder een voorbeeld:
<?xml version="1.0" encoding="UTF-8"?>
<plist version="1.0">
<dict>
<key>Label</key>
<string>my.service.app</string>
<key>WorkingDirectory</key>
<string>/Users/gebruiker/Projects/my.service.app/</string>
<key>ProgramArguments</key>
<array>
<string>/Users/gebruiker/Projects/my.service.app/my.service.app</string>
</array>
<key>RunAtLoad</key>
<true />
<key>KeepAlive</key>
<true />
<key>StandardOutPath</key>
<string>/Users/gebruiker/Library/Logs/my.service.app.log</string>
<key>StandardErrorPath</key>
<string>/Users/gebruiker/Library/Logs/my.service.app.log</string>
</dict>
</plist>
Plist xml's worden door MacOS (en IOS/IPadOS) voor diverse doeleinde gebruikt. Elke key waarde wordt opgevolgd door een waarde. In dit voorbeeld een "string", "array"of een "true" waarde. Welke key's er allemaal mogelijk zijn is afhankelijk van het doel waarbij deze ingezet wordt. Het is hierbij ook mogelijk om de applicaties op bepaalde tijdstippen te laten starten, zoals met cron onder linux ook kan.
Service console applicaties zijn dus niks meer dan console applicaties. Bij de ontwikkeling van DotNet Core, is ook de keuze gemaakt om (standaard) Dependency Injection te ondersteunen, net zoals in AspNet.Core. Uiteraard was dit niet zozeer iets nieuws, maar wel dat het out-of-the-box beschikbaar is. Er is in de applicatie een Main functie aanwezig (deze kan ook async gebruikt worden, waar gewenst).
using System;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
namespace my.service
{
class Program
{
static void Main(string[] args)
{
CreateHostBuilder(args).Build().Run();
}
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
// .UseSystemd() /* Te gebruiken voor linux services */
.ConfigureServices((hostContext, services) =>
{
services
.AddSingleton<SchedularContainer>()
.AddHostedService<SchedularWorker>()
.AddHostedService<InitWorker>();
});
}
}
Er wordt in ConfigureServices zowel de types geregistreerd, als ook de "HostedServices". Dit zijn objecten die overerven van "BackgroundService". Deze klasse verwacht dat er een ExecuteAsync(CancellationToken) wordt toegevoegd. Vervolgens bij het starten van de applicatie, worden alle ExecuteAsync methodes aangeroepen. Hierin kunnen dus specifieke onderdelen uitgevoerd worden.
using System;
using System.Collections.Generic;
using System.Threading;
using System.Threading.Tasks;
using Microsoft.Extensions.Hosting;
using Microsoft.Extensions.Logging;
namespace my.service
{
public class InitWorker : BackgroundService
{
public readonly ILogger Logger;
public InitWorker(ILogger<InitWorker> logger)
{
this.Logger = logger;
}
protected override Task ExecuteAsync(CancellationToken stoppingToken)
{
return Task.Run(() => { /**/ });
}
}
}
.Net 3.1, en opvolgend .Net 5.0 kunnen een applicatie publiceren die uitgevoerd kan worden zonder dat dotnet sdk of runtime geïnstalleerd zijn. Dit heeft als voordeel dat er geen gedoe is, of de juiste versie wel geïnstalleerd is of niet. Het minpunt is dat de applicatie wat groter is. Dit laatste vind ik het wel waard. Als de service in Docker uitgevoerd zou worden, zou ik ervoor kiezen om dit niet te doen, en de juiste Docker image te gebruiken. Hieronder een voorbeeld van het publiceren en installeren van de app als launchd service, zoals deze in bash uitgevoerd kan worden:
# Publiceer de applicatie as self-contained, specifiek voor MacOS 64 bits
dotnet publish -c release -r osx-x64 --self-contained true
# Kopieer de output naar de "installatie" lokatie
cp -r ./bin/release/net5.0/osx-x64/publish/* /Users/gebruiker/Projects/my.service.app && \
# Symlink de plist
ln -s /Users/gebruiker/Projects/my.service.app.plist ~/Library/LaunchAgents/my.service.app.plist
# Importeer de plist in launchd
launchctl load ~/Library/LaunchAgents/my.service.app.plist" ; \
# Start de service
launchctl start my.service.app
# Bekijk de output van de logfile
tail -F /Users/gebruiker/Library/Logs/my.service.app
Het maken van de symlink en Launchd load hoeft maar eenmalig uitgevoerd te worden bij de eerste installatie. Launchd kent zo een aantal commando's: start en stop, en load en unload. Via list wordt een lijst getoond van geregistreerde services.
Via tail -F wordt het laatste deel van de logfile getoond (en gevolgd) die afkomstig is van de applicatie. Launchd zal zelf zorgen voor het opruimen van de logsfiles.
Zonder ondersteuning van launchd in de DotNet applicatie, kan toch simpel een service gemaakt worden. Houdt er wel rekening mee, dat MacOS bedoeld is als Desktop omgeving. Services worden dan ook opgestart als een gebruiker ingelogd is, als deze in ~/Library/LaunchAgents is gedefinieerd. In mijn geval logt de "server" automatisch in als een specifieke gebruiker bij opstarten en dat zorgt ervoor dat alle services gestart worden. Via /Library/LaunchDaemons kan een service als root uitgevoerd worden, of een andere specifiek aangeven gebruiker, en gestart worden bij.
Om website die via Docker gehost worden, beschikbaar te maken voor het publiek, wordt veelal Nginx als webserver ertussen geplaatst. Waarom nginx? Op de website staat het volgende:
Because it can handle a high volume of connections, NGINX is commonly used as a reverse proxy and load balancer to manage incoming traffic and distribute it to slower upstream servers – anything from legacy database servers to microservices.
Nginx is relatief simpel te configureren en zou weinig negatieve effecten hebben op de doorvoer snelheid. Zoals de beschrijving aangeeft wordt hij ook veelal gebruikt als reverse proxy, en laat dat nou precies zijn wat we nodig hebben. Een reverse proxy is in dit geval een web server die tussen de gebruiker en een specifieke service zit. Zo 'praat' je niet rechtstreeks tegen de service. Hiernaast kunnen we ook zorgen dat Nginx het https deel op zich neemt, terwijl de service hier geen weet van heeft. Zo werd er tot een aantal Dotnet Core versie geleden, ook aangegeven dat voor productie websites het verstandig was om er een reverse proxy tussen te zetten (met https), aangezien toen Dotnet Core nog niet 'goed genoeg' was om zelf op te lossen.
Nog een reden om een reverse proxy te gebruiken, is het gebruik van virtual hosts. Dit betekend dat nginx meerdere websites kan 'hosten', met verschillende domeinnamen. Als we de website direct zouden hosten, zou deze poort 80 en/of 443 in gebruik nemen, zonder dat hier een 2de site gebruik van kan maken. De reverse proxy zorgt dat het juiste domeinnaam bij de juiste service terecht komt. Deze services hoeven overigens niet op dezelfde host te staan. Een good practice in het geval van services via docker, is dat deze services alleen intern op een host (of netwerk) te benaderen zijn, en niet rechtstreeks van buiten af.
In dit geval ga ik niet in op de volledige configuratie van nginx, die overigens ook via docker gehost wordt. Een kleine hint over de configuratie is dat er een intern docker netwerk gedefineerd is, waardoor nginx de hosts kan terug vinden. Hieronder een voorbeeld configuratie die zorgt dat verkeer voor www.willow-media.nl op poort 443 door wordt gestuurd naar willowmedia op poort 5000. 5000 is de standaard poort voor AspNet Core sites en willowmedia is de hostnaam van 1 van de docker instanties.
server {
server_name www.willow-media.nl;
listen 443 ssl http2;
listen [::]:443 ssl http2;
location / {
proxy_pass http://willowmedia:5000;
include /etc/nginx/proxy.conf;
}
# De rest van de configuratie is verwijderd
}
We lopen met deze configuratie meteen tegen een probleem aan. Als de docker container op het moment van (her)start van nginx niet beschikbaar is, zal nginx een foutmelding geven en niet starten. Hoewel dit meestal geen probleem is, is het vragen om problemen om dit niet op te lossen (laten we het maar even op Murphy's Law houden). Tijdens het starten van nginx wordt de hostnaam die bij de proxy_pass opgegeven is opgehaald bij de DNS. In dit geval is dat de DNS van docker. Dit gebeurd maar 1x, wat betekend dat als de host op dat moment niet te vinden is, nginx een foutmelding zal geven.
We kunnen dit probleem ondervangen door een variabele te gebruiken en deze te gebruiken voor proxy_pass. Echter was dit niet genoeg voor mijn situatie. Wat hiernaast ook nog kan voorkomen, is dat na het herstarten van een docker image, dat het (interne) IP nummer veranderd. Dit leid dan tot een "gateway error" vanuit nginx. Om dit op te lossen kan een resolver opgegeven worden, met een cache timeout. De resolver is in dit geval de DNS van docker, waarbij valid aangeeft hoe lang hij het IP nummer moet bewaren voordat hij op nieuw nagevraagd zal worden.
server {
server_name www.willow-media.nl;
listen 443 ssl http2;
listen [::]:443 ssl http2;
location / {
# this is the internal Docker DNS, cache only for 30s
resolver 127.0.0.11 valid=30s;
set $upstream http://willowmedia:5000;
proxy_pass $upstream;
include /etc/nginx/proxy.conf;
}
# De rest van de configuratie is verwijderd
}
30 seconden lijkt in dit geval veel, maar aangezien het incidenteel voorkomt dat het IP veranderd, wil ik voorkomen dat de DNS heel vaak geraadpleegd wordt. Uit ervaring zal moeten blijken of deze lager moet. Voor de volledigheid kan er ook nog een error pagina toegevoegd worden aan de configuratie, die bij een 502 (gateway error) statuscode een tijdelijke pagina laat zien. Deze zou na 30 seconden automatisch kunnen herladen om te kijken of de host weer benaderbaar is.